Unless you know you will need sustained access to superclusters, you should consider Lambda Labs alternatives.
This neocloud provides major AI horsepower, but their infrastructure comes at a premium price that not a lot of budgets can withstand. They offer discounts for long-term commitments, even still plenty of competitors offer cheaper on-demand instances giving you instant savings and flexibility.
Quick picks
Depending on your needs these are the best Lambda Labs competitors:
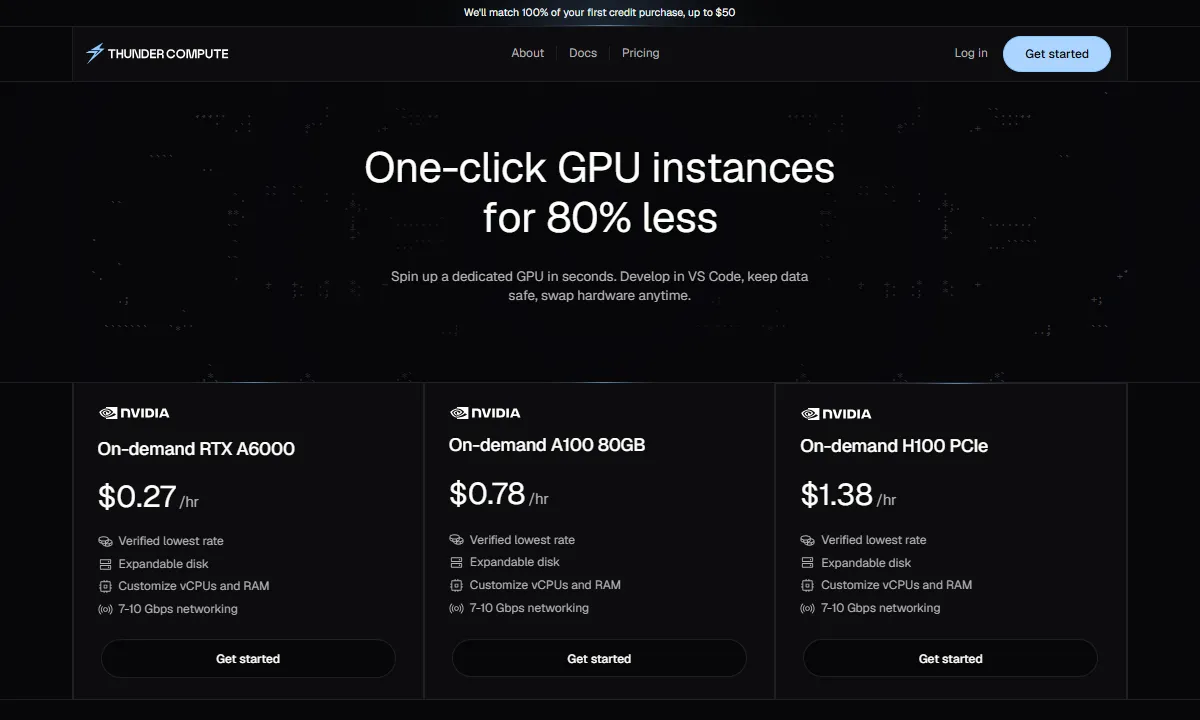
- Cheapest on-demand A100/H100 -> Thunder Compute - per-minute billing, persistent storage, VS Code integration.
- Large marketplace with consumer cards -> Vast.ai - crowdsourced supply, many RTX 4090 options.
- Enterprise-y alternative with public rates -> Crusoe.
- Serverless and workflows -> Modal - per-second rates translate to ~$2.50/hr for A100, ~$3.95/hr for H100.
- Broad ecosystem and notebooks -> Paperspace - H100 on-demand ~$5.95/hr; A100 also available.
Pricing snapshot (A100 and H100)
Rates are on-demand list prices. Some providers sell multi-GPU nodes, but the figures shown are per-GPU for easy comparison.
| Provider | A100 80 GB ($/hr) | H100 80 GB ($/hr) | Notes |
|---|---|---|---|
| Thunder Compute | 1.09 | 2.19 | Per-second billing, persistent storage 0.15/GB/mo, snapshots, change vCPU/RAM on the fly, one-click VS Code. |
| Lambda Labs | 2.79 | 3.99 | Published per-GPU price for A100 and H100 PCIe. |
| Runpod | 1.39 | 2.89 | A100 80 GB on-demand, H100 starts at 2.89. |
| Crusoe Cloud | 1.65 | 3.90 | Public on-demand table. |
| Modal | ~2.50 | ~3.95 | Per-second rates converted to hourly. |
| Paperspace | 3.18 (80 GB) | 5.95 | On-demand per official docs. |
Rates updated on: June 2, 2026.
Marketplace vs managed clouds (important if you need consumer GPUs)
Marketplaces can deliver the lowest cost, but host consistency varies.
- Vast.ai is a decentralized, peer-to-peer marketplace aggregating GPUs from both individuals and datacenters. It includes consumer-grade GPUs like the RTX 4090 resulting in high supply variability and often lower prices.
- Runpod Community Cloud also lists consumer GPUs with transparent starting prices and community-provided capacity.
If consistent performance, multi-GPU NVLink, or enterprise networking matters, you need the predictability of managed clouds (Thunder Compute, Lambda Labs, Crusoe).
Why teams pick Thunder Compute
- Low on-demand A100/H100 rates
- A100 80 GB for $1.09/hr
- H100 for $2.19/hr
- Great developer experience with one-click VS Code integration, per-minute billing, persistent disks, snapshots, dynamic vCPU/RAM adjustments.
- Simple pricing, check out the Thunder Compute pricing page for up-to-date details.
- Reliable storage for $0.15/GB/month.
- No egress fees
How to choose
- For multi-GPU training with fast interconnect: opt for managed providers that explicitly publish SXM node specs and interconnect performance.
- For fast development or fine-tuning: prioritize per-second billing, quick restart speeds, and persistent storage.
- To minimize cash burn: compare hourly A100 vs H100 costs. If possible choose A100 GPUs which offer more cost-effective compute per token for development models.
- For small workloads: consider consumer GPUs for image generation or lightweight training, but verify VRAM, driver compatibility, and host stability.
Final Thoughts
For most teams, exploring Lambda Labs alternatives is necessary to optimize for cost, flexibility, and workflow fit.
Lambda Labs still makes sense if you need tightly integrated multi-GPU clusters and are comfortable committing to higher pricing. But for many real-world use cases there are multiple providers offering similar performance for lower on-demand rates.
Unless you specifically need Lambda Labs' supercluster setup, testing a few alternatives can quickly translate into meaningful savings.