Ollama is an open-source platform for running AI models locally, with no ongoing API costs and full control over your data.
This guide covers everything you need to get started, plus how to run Ollama workflows on a dedicated GPU cloud for only $0.35/hour.
Takeaways
- Deploy models like DeepSeek and Llama in minutes with no ML expertise.
- Local deployment keeps sensitive data on your infrastructure, with no per-token fees.
- Thunder Compute provides dedicated GPU resources when local hardware hits its limit.
- Ollama now supports cloud models and coding agent integrations alongside local inference.
What is Ollama
Ollama is an open-source platform for running and managing LLMs on your own machine or through hosted cloud models. It packages model weights, configurations, and datasets into a unified "Modelfile", reducing setup to a single command.
Unlike proprietary cloud services, Ollama gives you complete control over your models and data. The installation is straightforward, and the same CLI and API work whether you are running a model locally or routing it through Ollama's cloud infrastructure.
Ollama vs Cloud AI: How Do They Compare?
Ollama and cloud AI services like ChatGPT or Claude solve different problems. Here's how they stack up:
| Ollama (Local) | Cloud AI (ChatGPT / Claude) | |
|---|---|---|
| Data Privacy | Complete — data never leaves your machine | Data processed on vendor servers |
| Cost | Free to run; pay only for hardware or GPU time | Per-token API fees or $20+/month subscriptions |
| Internet Required | Local models: No. Cloud models (kimi-k2.6:cloud, etc.): Yes |
Yes — always requires a connection |
| Model Choice | 4,500+ open-weight models (Llama 4, DeepSeek R1, Kimi K2, Mistral…) | Limited to provider's own models |
| Setup Time | ~5 minutes | Instant (browser-based) |
| Best For | Privacy-sensitive work, cost control, offline use, regulated industries | General use, multimodal tasks, no technical setup |
Choose Ollama when your data can't leave your infrastructure, API bills are climbing, or you need to work offline. Choose cloud AI when you need frontier reasoning or built-in multimodal features without any setup.
How Ollama Works
Ollama creates an isolated environment to run LLMs locally, preventing conflicts with other installed software. This environment includes all necessary components for model deployment.
Setting up Ollama
- Download the installer from the official Ollama website.
- Run the installer and open your terminal.
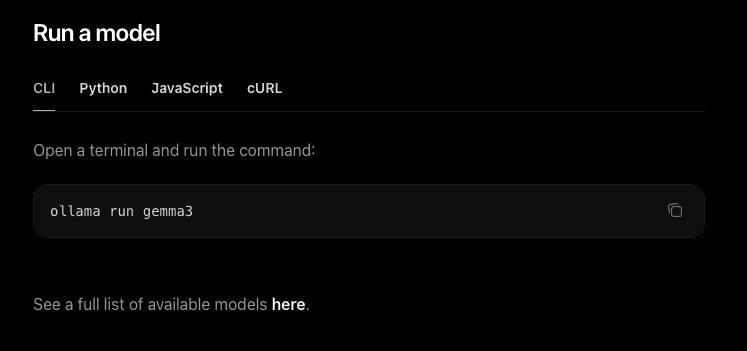
- Run a model:
ollama run llama3.2
After setup, enter prompts and the model will generate responses just like ChatGPT or Claude.
The Significance of Quantization
Quantization: reducing the numerical precision of a model's weights and activations, making models smaller and more memory-efficient with a small trade-off in accuracy.
Ollama uses quantization to optimize model performance on consumer hardware. Models requiring lots of VRAM can often be compressed to run on just 8 GB. CUDA installations, dependency management, and memory allocation are all handled automatically.
Ollama's REST API and OpenAI Compatibility
Ollama exposes a local REST API at http://localhost:11434 that mirrors the OpenAI Chat Completions API. Any tool or framework built for OpenAI (LangChain, LlamaIndex, CrewAI, Continue) works with Ollama without code changes. Claude Code and other Anthropic-compatible tools connect via ANTHROPIC_BASE_URL=http://localhost:11434.
This API compatibility is one of the main reasons developers adopt Ollama over running llama.cpp directly. The same endpoint works whether the model is running locally or through a cloud tag.
Cloud Models and the ollama launch Command
Ollama has expanded well beyond local inference. Two features define how most developers use it in 2026.
Cloud models carry a :cloud suffix (e.g., kimi-k2.6:cloud, deepseek-v4-pro:cloud) and run on Ollama's own servers rather than your local GPU. You use the exact same CLI and API as local models, with ollama signin required and an internet connection per request. Cloud models are useful when a model is too large for your hardware or you want fast inference without managing GPU resources.
ollama launch starts a full coding agent environment in one command, with Ollama as the backend:
ollama launch claude
ollama launch codex-app
ollama launch opencode
ollama launch openclaw
These integrations work with both local and cloud models — swap the model tag and the agent picks it up automatically.
Ollama System Requirements
System requirements vary significantly based on the model you want to run.
Model Parameters
Parameters: numerical values a model learns during training.
The number in a model's name (7B, 13B, 70B) indicates its parameter count. More parameters generally means more capable responses, but also higher memory requirements. When a model runs, all parameters must be loaded into VRAM or RAM. A useful rule for 4-bit quantization: allow 1.2 GB of VRAM per 1B parameters.
Why VRAM is King for AI
System RAM transfers data at 20-70 GB/s, whereas VRAM moves data at 350-4,800 GB/s. That bandwidth gap is why GPU inference is so much faster. If a model exceeds your VRAM, Ollama offloads the remaining layers to system RAM, which prevents a crash but reduces tokens-per-second sharply. Always aim to keep the full model in VRAM.
For a full breakdown of which GPU fits your workload and budget, see the Thunder Compute guide to the best GPU for LLM work.
Available Models on Ollama
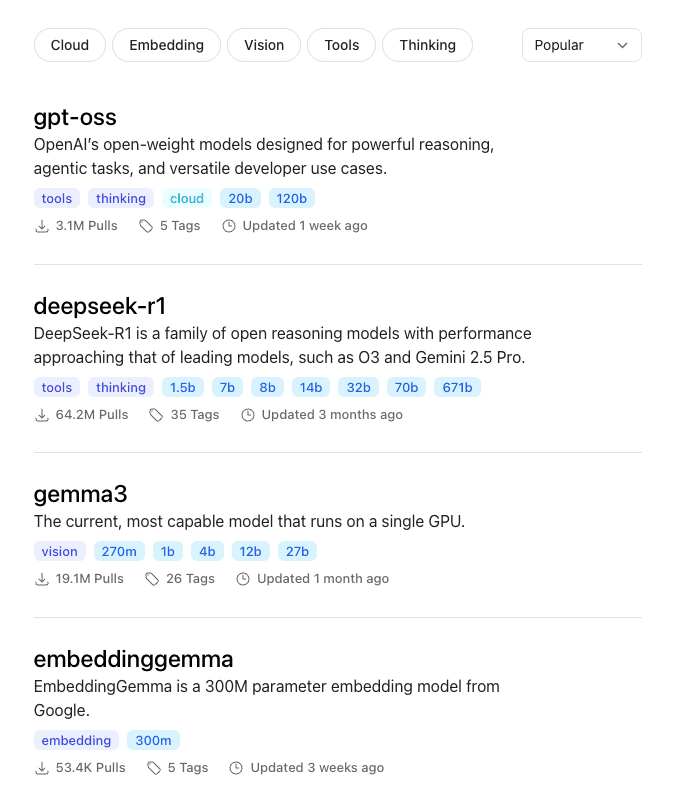
Ollama's model library covers a wide range of use cases, from lightweight assistants to frontier reasoning models. Popular options:
| Model Family | Best For | Parameter Sizes | Key Features |
|---|---|---|---|
| DeepSeek R1 | Complex reasoning, math | 1.5B-671B | Chain-of-thought reasoning |
| Llama 4 | General conversation, multimodal | Scout 109B, Maverick 400B | Meta's latest MoE models |
| Mistral | Fast performance, balanced tasks | 7B-22B | Optimized for speed and accuracy |
| Gemma 3 | Lightweight applications | 1B-27B | Google's efficient models |
| Kimi K2 | Coding, agentic tasks | 1T (32B active) | Top open-source coding model |
For step-by-step guides on running today's most capable models, see:
- How to run DeepSeek R1 with Ollama: the full 671B reasoning model on cloud GPUs
- How to run Kimi K2 with Ollama: the top open-source coding model at 1T parameters
- How to run Llama 4 with Ollama: Scout and Maverick, Meta's multimodal MoE family
Use Cases and Applications
Ollama serves diverse use cases across different industries.
Development: Developers use Ollama for code completion, programming assistance, document analysis, and research with proprietary datasets. There are no API costs or rate limits to work around.
Business Applications: Companies in regulated industries benefit most from local deployment. Customer service chatbots, internal knowledge base querying, content generation, and legal document analysis are all possible without exposing data to third-party servers.
Education: Institutions use Ollama to eliminate ongoing cloud costs for teaching AI concepts, student projects, and academic research.
One of the strongest reasons to run models locally is compliance. Many industries operate under strict data privacy regulations that make cloud solutions risky. Ollama ensures the entire inference process stays on your infrastructure.
Why Run Ollama in the Cloud?
Local execution works well for small models, but frontier models require hardware most teams don't own. An NVIDIA H100 runs from around $25,000; a dedicated RTX PRO 6000 around $13,250 as of June 2026.
Thunder Compute provides pre-configured Ollama templates with access to enterprise GPUs like the NVIDIA A100 and NVIDIA H100, without the upfront cost. You get the same privacy benefits of local deployment with the performance of enterprise hardware.
Step-by-Step: Running Ollama on Thunder Compute
Thunder Compute's one-click Ollama template handles NVIDIA drivers and CUDA automatically. Nothing to configure.
Step 1: Create a GPU Instance
Create a Thunder Compute instance with the following configuration:
- GPU: NVIDIA RTX A6000*
- Size: 4vCPUs (32GB RAM)*
- Template: Ollama
- Disk: 100GB
*Starting point only; adjust GPU and disk based on the model you plan to run.
The environment comes pre-loaded with Ubuntu 22.04, NVIDIA Drivers, and the Ollama binary.
Step 2: Connect
Once your instance is live, connect using VSCode, Cursor, or your OS's CLI.
Step 3: Start Ollama
Run start-ollama to initialize Open WebUI. This returns a link to access the platform.
Step 4: Add a Model
The template ships with no models pre-installed.
- Head over to the Ollama Models page.
- Select a model.
- Go back to Open WebUI.
- Click Select a model.
- Type the model name to begin the download.
Download time depends on model size.
Step 5: Start Chatting
Your model is now live. Send a complex prompt, ask it to write a Python script, or use it to analyze a dataset.
Last Thoughts on Ollama
Ollama puts powerful AI tools on your machine without ongoing costs or privacy concerns. Start locally for full control over your data and models. When projects outgrow local hardware, Thunder Compute provides dedicated GPU resources while maintaining that same control.
FAQ
What hardware do I need to run Ollama effectively?
A dedicated NVIDIA GPU is recommended. For small models (3B-8B), 8 GB of VRAM is sufficient. Larger models need 24-80 GB of VRAM, which typically means a cloud GPU instance rather than consumer hardware.
How does Ollama compare to ChatGPT?
Ollama runs on your local machine with no ongoing costs and full data privacy. Cloud services like ChatGPT require internet access and charge per use, but offer more powerful frontier models without any hardware setup.
Can I use Ollama for commercial applications?
Yes, Ollama is free for commercial use with no licensing fees. This makes it attractive for businesses that need AI features while keeping data on their own infrastructure.
When should I consider moving from local Ollama to cloud infrastructure?
Move to cloud when local hardware can't handle the model size you need, when you require consistent production performance, or when your team needs shared access to GPU resources.
Can I use Ollama without a GPU?
Yes. Ollama supports CPU-only execution, but expect only a few words per second. A dedicated GPU is strongly recommended for anything beyond light testing.
Where does Ollama store models?
On Linux, models are stored in /usr/share/ollama/.ollama/models (system install) or ~/.ollama/models (user install). On Mac, they are in ~/.ollama/models, and on Windows in C:\Users\<username>\.ollama\models. Large frontier models can consume hundreds of GB, so monitor disk space carefully.
Is Ollama free?
Yes, Ollama is free and open source. Running models locally costs nothing beyond your hardware. Cloud GPU time on Thunder Compute starts at $0.35/hour, with no per-token fees.
What models can I run with Ollama?
Ollama's library has 4,500+ models including Llama 4, DeepSeek R1, Kimi K2, Qwen 3.6, Mistral, Gemma, and Phi-4. Run ollama list to see what you have installed, or browse ollama.com/library for the full catalogue.
What are Ollama cloud models?
Cloud models carry a :cloud suffix (e.g., kimi-k2.6:cloud) and run on Ollama's own servers instead of your local GPU. They use the same CLI and API as local models. Run ollama signin first, then use them exactly like any other model. An internet connection is required per request.
What is ollama launch?
ollama launch starts a full coding agent environment using Ollama as the backend. For example, ollama launch claude starts Claude Code, ollama launch codex-app starts the Codex App, and ollama launch openclaw starts OpenClaw. Both local and cloud models are supported.