This guide provides a framework to pick the best GPU for AI workloads, from calculating VRAM requirements to scaling resources dynamically as your project evolves.
We're obsessed with optimizing GPU compute for teams. We've seen the same costly mistake over and over: choosing the wrong GPU resulting in massive training times or projects crashing.
Most teams struggle to choose the GPU they need because the requirements vary dramatically between fine-tuning existing models, running inference, and training from scratch.
Key takeaways:
- Match VRAM to model size: a 7B model can often be fine-tuned on a single 24-40GB GPU.
- VRAM needs scale by workload: inference requires the least, fine-tuning typically needs ~1.5-2x inference VRAM, and full training can be 4x heavier
- Scaling usually means multi-GPU: moving from 1 GPU to 4-8 A100s/H100s is more common than upgrading to a single larger GPU.
- Thunder Compute lets you swap GPU types mid-project without losing your environment.
- Start small for development, scale up for training, then optimize for production costs.
.png)
Why GPU Selection Matters for AI Projects
Picking the best GPU infrastructure for your project will determine its success. Teams can waste development time and thousands of dollars simply because they picked the wrong hardware for their workload.
The good news? Cloud GPU services eliminate risk. You can test different configurations, measure actual performance on your workloads, and adjust resources as needed without massive upfront investments.
Iteration Speed Impact
Your GPU choice directly determines how quickly you can run fine-tuning jobs and re-train variations of your model.
A fine-tune that finishes in 2 hours on an A100 might take much longer on an A6000. It's not just a matter of convenience, it's the difference between running multiple experiments in a single day versus waiting days for results.
This inevitably translates into added costs. For example, 10 hours on an A6000 cost $3.50, meanwhile 2 hours on an A100 are $2.18. You're effectively paying about 38% less to get your results 5x faster.
Faster iteration means faster model improvement, lower overall costs, and quicker deployment into production.
Memory Constraints
VRAM limitations are the most common project killer. If your model doesn't fit in GPU memory, it simply won't fine-tune or train. Period. Beyond a certain point you can't work around insufficient VRAM with clever optimization tricks.
Cost Savings
The wrong GPU wastes money in multiple ways. Overpowered GPUs burn budget on unused features, while underpowered ones extend training times and increase total costs. GPU cloud services help optimize this balance by letting you match resources to workloads precisely.
Scalability Limitations
Scaling from prototype to production usually means moving from 1 GPU to 4-8 GPUs. This is where A100s and H100s shine, as they're designed for efficient multi-GPU scaling with NVLink and high memory bandwidth. Choosing the right hardware is the first step to avoid multi-GPU training bottlenecks.
Framework Compatibility
Different GPUs have varying levels of support for ML frameworks and optimization libraries. Newer architectures often provide better performance with the latest versions of PyTorch, TensorFlow, and specialized libraries like Hugging Face Transformers.
Assess Your VRAM Requirements
Model Size Calculations
Full model training is rare and extremely resource-intensive. A 7B parameter model can require ~112GB VRAM for full training, which usually means multi-GPU clusters. Most teams don't do this from scratch.
For inference, you typically need: Model Parameters x 2 bytes (for half-precision). That same 7B model requires about 14GB for inference, making it feasible on smaller GPUs.
Fine-tuning VRAM Needs
For most teams, fine-tuning a pre-trained model is the practical path. Parameter-efficient methods like LoRA and QLoRA cut VRAM requirements dramatically:
- LLaMA 7B can be fine-tuned on a single 24-40GB GPU.
- LLaMA 13B typically fits on an A100 40GB.
- Even larger models can often be fine-tuned across 2-4 GPUs with data parallelism.
Instead of the 4x VRAM multiplier that full training requires, fine-tuning often falls within 1.5-2x the inference VRAM footprint.
Batch Size Impact
Larger batch sizes improve training speed but require more VRAM. If you're working with limited memory, you can use gradient accumulation to simulate larger batches while using smaller actual batch sizes.
Popular Model VRAM Requirements
Here are approximate VRAM needs for common models:
| Model | Inference VRAM | Fine-tuning VRAM (LoRA/QLoRA) |
|---|---|---|
| GPT-2 (1.5B) | 3GB | ~6GB |
| LLaMA 7B | 14GB | ~24GB (40GB recommended for headroom) |
| LLaMA 13B | 26GB | ~40GB |
| LLaMA 70B | 140GB | Multi-GPU (4-8x A100/H100) |
When fine-tuning pushes past single-GPU limits, the natural step isn't upgrading to a larger single card, but moving to 4-8 GPUs. This is where NVLink on A100s and H100s really matters, allowing large-batch or large-model fine-tuning without rewriting your workflows.
Optimization Techniques
Several techniques can reduce VRAM requirements:
- Mixed precision training (FP16/BF16)
- Gradient checkpointing
- Model parallelism across multiple GPUs
- Parameter-efficient fine-tuning (LoRA, QLoRA)
- Gradient accumulation
Understanding your actual VRAM needs helps you choose the most cost-effective GPU without overprovisioning resources.
Choose the Right GPU Architecture
Different GPU architectures excel at different types of AI workloads. Understanding these strengths helps you optimize both performance and cost.
RTX A6000 - Applications
RTX A6000 is a great entry-level option GPU for LLM workloads. They're cost-effective for inference, development, and fine-tuning smaller models. With QLoRA and aggressive quantization, it's technically possible to fine-tune a 7B model on an A6000, but performance is limited and not practical for production.
A6000s are the best budget GPUs for ai inference workloads where you need consistent performance at low cost. They're also excellent for development and experimentation before scaling to larger GPUs for production training.
For a detailed head-to-head breakdown, see NVIDIA RTX A6000 vs A100: which GPU fits your workload?
L40 - Applications
The L40 is a strong mid-tier option for inference. With 48GB of VRAM and Ada Lovelace architecture, it handles a broader range of workloads than the A6000 while coming in at a lower cost than the A100.
L40s are great for inference and fine-tuning small models, particularly if you need more throughput than an A6000 can provide but don't require the full memory bandwidth of an A100. It's also used for computer vision pipelines and multimodal workloads that benefit from its improved image processing capabilities.
Its biggest drawback is not supporting fast multi-GPU configurations. Without NVLink support, it's less efficient than A100s when scaling across multiple cards. For pure training jobs on models with 13B+ parameters, a single A100 80GB delivers better performance.
Understand the difference between the NVIDIA L40 and the L40S.
A100 - Applications
A100 GPUs are the sweet spot for most AI training workloads. Available in 40GB and 80GB VRAM configurations, they provide third-generation Tensor cores and much higher memory bandwidth than T4s.
The 80GB variant handles most practical training scenarios, including fine-tuning AI models and training medium-sized models from scratch. A100s also support multi-instance GPU (MIG) technology, allowing you to partition a single GPU into smaller instances for better resource use.
Explore NVIDIA A100 specifications in depth.
H100 - Applications
H100s are cutting edge GPUs for LLM training, designed for the largest and most demanding AI workloads. They feature fourth-generation Tensor cores, massive memory bandwidth, and advanced interconnect technologies for multi-GPU scaling.
H100s excel at training very large models, running inference on massive language models, and research workloads that push the boundaries of what's possible. However, they're overkill for most practical applications and much more expensive.
Discover the characteristics of NVIDIA H100 GPUs.
GPU Selection Guidelines
Choose RTX A6000 for:
- Inference workloads
- Small model training (under 1B parameters)
- Prototyping and development
- Computer vision tasks
- Budget-conscious projects
Choose L40 for:
- Mid-sized model fine-tuning (7B–13B parameters)
- High-throughput inference workloads
- Computer vision pipelines
- Single-GPU workloads that outgrew the RTX A6000
Choose A100 for:
- Medium to large model training
- Fine-tuning advanced models
- Production inference for large models
- Multi-GPU training setups
Choose H100 for:
- Cutting-edge research
- Training models over 70B parameters
- High-throughput inference for very large models
- Unless you're training 70B+ parameter models, scaling multiple A100s delivers better ROI than jumping to a single H100
The flexibility of cloud GPU services means you can start with one architecture and upgrade as your needs grow. This approach minimizes risk and optimizes costs throughout your project lifecycle.
GPU Spec Comparison
Here's how the most widely used AI GPUs compare across the specs that matter most for AI workloads:
| GPU | VRAM | Memory Bandwidth | FP16 TFLOPS | Cloud Price (on-demand) | Best For |
|---|---|---|---|---|---|
| RTX 4090 | 24GB GDDR6X | 1,008 GB/s | 82.6 | Local (~$1,600 used) | Local dev, 7B–13B inference |
| RTX A6000 | 48GB GDDR6 | 768 GB/s | 38.7 | from $0.35/hr | Inference, dev, small fine-tunes |
| L40 | 48GB GDDR6 | 864 GB/s | 90.5 | from $0.79/hr | Mid-scale inference, CV pipelines |
| A100 80GB | 80GB HBM2e | 2,039 GB/s | 312 | from $1.09/hr | LLM fine-tuning, production training |
| H100 80GB | 80GB HBM3 | 3,350 GB/s | 989 | from $2.19/hr | Large model training, fast inference |
| H200 80GB | 141GB HBM3e | 4,800 GB/s | 989 | ~$4–6/hr (varies by provider) | 70B+ training, long-context inference |
| B200 | 192GB HBM3e | 8,000 GB/s | 2,250 | ~$8–12/hr (varies by provider) | Frontier model training, max throughput |
| Memory bandwidth figures are for SXM variants where applicable. Cloud pricing is on-demand and varies by provider; see our cheapest cloud GPU providers guide for a full comparison. | |||||
The bandwidth gap between GDDR6-based GPUs and HBM-based data center cards explains why an A100 often outperforms a GPU with higher raw TFLOPS. AI training is mostly memory-bound, so faster data movement translates directly into faster iteration. RTX A6000, L40, A100, and H100 are all available on Thunder Compute — see the pricing page for current rates.
Match GPU Type to Workload Requirements

LLM Training
LLM training demands high VRAM and memory bandwidth. Full training of models over 7B parameters typically requires A100 80GB or H100 GPUs. The massive parameter counts and long sequence lengths create substantial memory pressure.
For LLM training, focus on VRAM capacity over raw compute power. Memory bandwidth also matters a lot because these models spend considerable time moving data rather than computing.
Fine-tuning Workflows
Fine-tuning is more forgiving than full training. Techniques like LoRA allow fine-tuning of large models on smaller GPUs. An RTX A6000 can handle fine-tuning of most models up to 13B parameters with proper optimization.
Parameter-efficient fine-tuning methods have democratized access to large model customization. While you can fine-tune a 7B model on a T4 with QLoRA, most teams prefer an RTX A6000 for increased training speeds
Compare NVIDIA A100 vs RTX 4090 for fine-tuning
Computer Vision Tasks
Computer vision workloads often benefit more from compute power than extreme VRAM capacity. Image classification, object detection, and segmentation models typically fit comfortably in 16-40GB VRAM.
An RTX A6000 can handle most computer vision tasks effectively. The choice depends more on training speed requirements than memory constraints.
Choose the best GPU for computer vision projects.
Inference Workloads
Inference optimization focuses on throughput and latency rather than training performance. RTX A6000 GPUs often provide the best cost-performance ratio for inference, especially when serving multiple smaller models or handling variable loads.
For large model inference, A100s provide better throughput per dollar despite higher hourly costs. The key is matching GPU capacity to your expected request volume.
Consider the differences between NVIDIA L40 vs A100 GPUs
Research and Experimentation
Research workloads benefit from flexibility more than any specific optimization. The ability to quickly switch between GPU types as experiments evolve is important. Thunder Compute excels here by allowing hardware changes without environment reconfiguration.
If you're evaluating whether a GPU is the right accelerator for your workload at all, see TPU vs GPU for AI: a full comparison.
Multi-GPU Considerations
Some workloads scale well across multiple GPUs while others don't. Model parallelism works well for very large models, while data parallelism suits smaller models with large datasets. A100 and H100 GPUs provide better multi-GPU scaling than RTX A6000s.
Understanding your workload characteristics helps you choose the most appropriate GPU type and avoid both performance bottlenecks and unnecessary costs.
Compare NVIDIA A100 vs H100 for multi-GPU instances.
Scale and Optimize Your GPU Usage
Effective GPU usage goes beyond initial selection. Monitoring performance, adjusting resources as needed, and optimizing costs throughout your project lifecycle maximizes value.
GPU Performance Monitoring
Track key metrics to understand if your GPU choice is optimal:
- GPU utilization: Should stay above 80% during training.
- Memory utilization: Aim for 85-95% of available VRAM.
- Training throughput: Measure samples per second or tokens per second.
- Cost per epoch: Track total fine-tuning and training costs over time.
Low GPU utilization often indicates CPU bottlenecks, inefficient data loading, or suboptimal batch sizes. High memory utilization with low compute utilization suggests memory bandwidth limitations.
Advanced Optimization Features
Thunder Compute's GPU orchestration provides unique optimization features:
- Swap GPU types without losing your environment
- Persistent storage maintains data across instance changes
- VS Code integration speeds up development workflows Instance templates accelerate common setup tasks
Scaling Strategies
Plan your scaling approach based on project phases:
Development: Use cost-effective GPUs for code development and small-scale testing Training: Scale to appropriate GPUs based on model size and timeline requirements Production: Optimize for inference throughput and cost savings Maintenance: Use minimal resources for monitoring and occasional retraining
Multi-GPU Scaling
When single GPUs become insufficient, consider multi-GPU approaches:
Data parallelism: Distribute batches across multiple GPUs Model parallelism: Split large models across multiple GPUs Pipeline parallelism: Process different model layers on different GPUs Hybrid approaches: Combine techniques for maximum performance
The key to successful scaling is maintaining flexibility. Avoid locking into specific hardware configurations too early in your project lifecycle.
Why Thunder Compute is the Best Option

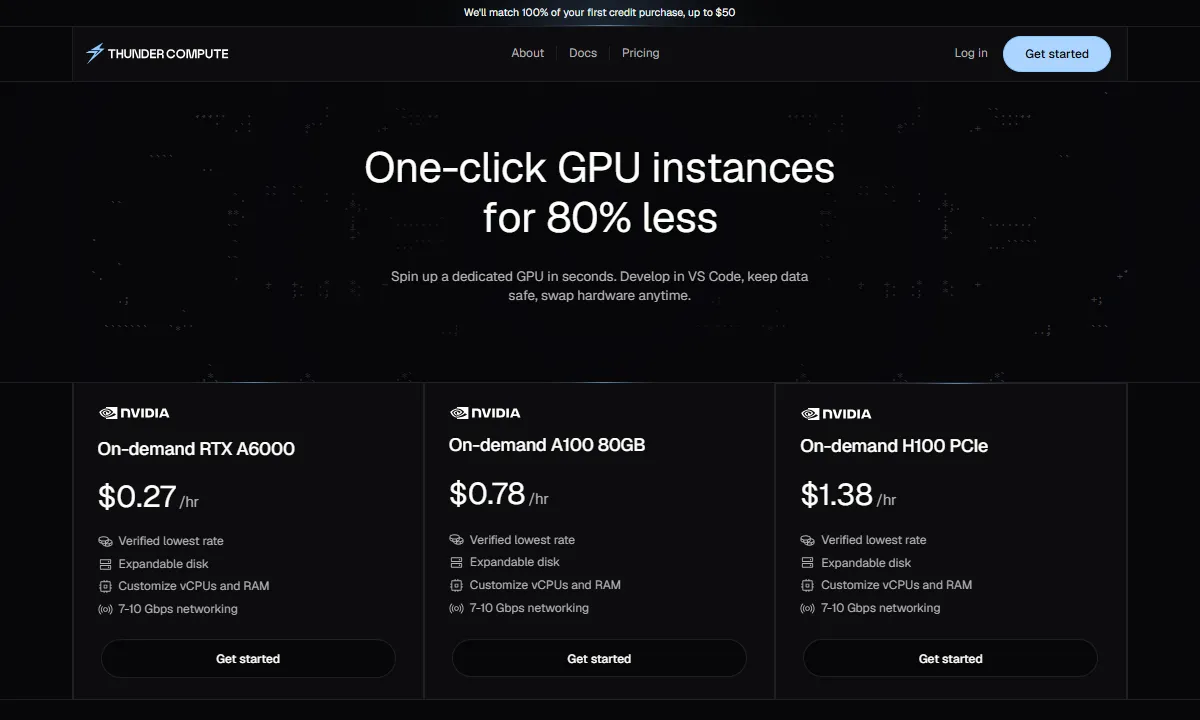
- Up to 80% cheaper than major cloud providers like AWS. Thunder Compute delivers on-demand GPU instances, including RTX A6000, A100 80 GB, and H100 80 GB at significantly lower hourly prices.
- Our pay-per-minute billing model ensures you're only charged for what you use. No more paying for idle minutes.
- One-command provisioning: You can go from CPU-only dev to GPU cluster via CLI in one line. No setup hassle.
- VS Code integration: Spin up, connect, and switch GPUs directly from your IDE. No complex config or deployment needed.
- Persistent storage, snapshots, spec changes: You can upgrade or modify your instance (vCPUs, RAM, GPU type) without tearing down your environment.
Final Thoughts on Selecting the Best GPU for AI Workloads
The GPU decision doesn't have to be permanent or perfect from day one. Most teams benefit from starting smaller and scaling up as their models and requirements evolve. If you're still unsure about choosing the best GPU for ai workloads, Thunder Compute's flexible cloud environment removes much of the guesswork for up to 80% off.
FAQ
What's the main difference between A6000, A100, and H100 GPUs for AI workloads?
A6000 GPUs (48GB VRAM) are cost-effective for inference and small model training, A100 GPUs (40GB/80GB VRAM) handle most practical training scenarios including LLM fine-tuning, and H100 GPUs (80GB VRAM) are designed for cutting-edge research and the largest models. The choice depends on your model size, budget, and performance requirements.
When should I switch from a smaller GPU to a larger one during my project?
Start with a single GPU for development, then scale out to 4-8 GPUs when fine-tuning at production scale. If your model won't fit or training/fine-tuning is too slow, that's when you add more GPUs. Thunder Compute lets you make this jump seamlessly.
What's the best budget GPU for AI?
In short, it's the cheapest GPU that supports your project. If you want to work with the latest models without investing huge amounts of time and money, a cloud GPU is always the most cost effective option.
How to pick optimal GPUs for LLM workloads?
It's a balancing act between VRAM, computing power and model configurations. A good rule of thumb is to start small and scale up as needed. And the best way to achieve that is through cloud GPUs.