CUDA Cores are the parallel processors inside NVIDIA GPUs that make AI models train way faster on GPUs than on CPUs. Each core handles floating point operations, and thousands run at once. Core count alone does not decide performance.
This guide covers what CUDA cores do, how they compare with Tensor Cores, and which specs matter when you choose a GPU for AI training.
Takeaways:
- CUDA Cores run thousands of operations in parallel, making AI training up to 10-20x faster than CPU training.
- More CUDA Cores don't guarantee better performance. Memory bandwidth, architecture, and Tensor Cores matter just as much.
- CUDA Cores handle floating-point computations; Tensor Cores run matrix operations.
- Thunder Compute runs CUDA-powered GPU instances from $0.35/hr, with the A100 80GB at $1.09/hr and H100 at $2.19/hr.

What Does CUDA Stand for?
CUDA stands for Compute Unified Device Architecture, NVIDIA's proprietary parallel computing platform and toolkit. CUDA the platform is not the same as CUDA cores, which are the physical processing units built into NVIDIA GPUs.
CUDA cores are hardware and operate independently of any software. The CUDA platform is what developers use to write code that programs those cores, tapping thousands of them in parallel to accelerate compute-heavy tasks.
What Are CUDA Cores?
CUDA Cores are the fundamental processing units inside NVIDIA GPUs that handle parallel computation. Each CUDA Core executes basic arithmetic operations: addition, multiplication, and floating-point calculations.
A CPU might have up to 20 cores optimized for complex sequential tasks. A single GPU contains thousands of CUDA Cores designed for simple, repetitive operations.
Modern CUDA cores include a Fused Multiply-Add (FMA) unit that performs a multiplication and an addition simultaneously (A times B + C), counting as two operations per clock cycle.
An RTX 4090 has 16,384 CUDA cores; at a clock rate of 2,235 MHz, they alone deliver roughly 70 trillion FP32 operations per second.
CUDA Cores turned GPUs from graphics-only devices into general-purpose computing engines. Developers applied them to scientific computing, cryptocurrency mining, and eventually machine learning. Any workload that splits into many small, independent calculations runs efficiently on CUDA Cores.
Each CUDA Core runs at a lower clock speed than a CPU core, but thousands working together produce far greater total throughput. Training a neural network with millions of parameters rewards many slow cores over a few fast ones. That trade-off is why choosing the right GPU for AI workloads changes training times so dramatically.

Brief Overview of CUDA Architecture
CUDA cores are housed within Streaming Multiprocessors (SMs), the building blocks of NVIDIA GPUs. The GPU scheduler groups threads into warps of 32 and executes them in lockstep, which keeps thousands of CUDA cores busy.
CUDA relies on a memory hierarchy of registers, shared memory, and global memory. GPU performance therefore depends on both raw compute and how efficiently data moves around the chip.
CUDA Cores vs Tensor Cores
CUDA Cores and Tensor Cores serve different purposes on the same NVIDIA GPU. Knowing which one your workload uses helps you pick hardware.
CUDA Cores are the generalists. They handle standard floating-point operations, integer math, and general-purpose parallel computing tasks. Every NVIDIA GPU since 2006 has included CUDA Cores.
Tensor Cores are the specialists. Introduced with the Volta architecture in 2017, these cores are built for deep learning operations. Tensor Cores excel at matrix multiplication in mixed-precision formats like FP16, BF16, and INT8.
| Feature | CUDA Cores | Tensor Cores |
|---|---|---|
| Purpose | General parallel computing | Deep learning matrix operations |
| Precision | FP32, FP64, INT32 | FP16, BF16, INT8, TF32 |
| Performance | Good for diverse workloads | Exceptional for AI training/inference |
| Availability | All NVIDIA GPUs since 2006 | RTX 20-series and newer, data center GPUs |
Tensor Cores can deliver neural network training speeds up to 20x faster than CUDA cores alone. They achieve this by performing fused multiply-add operations on 4x4 matrices in a single clock cycle.
CUDA Cores and Tensor Cores complement each other. During AI training, Tensor Cores handle the heavy matrix multiplications in transformer attention layers and convolutions, while CUDA Cores manage data preprocessing, activation functions, and other operations that don't fit Tensor Cores' specialized design.
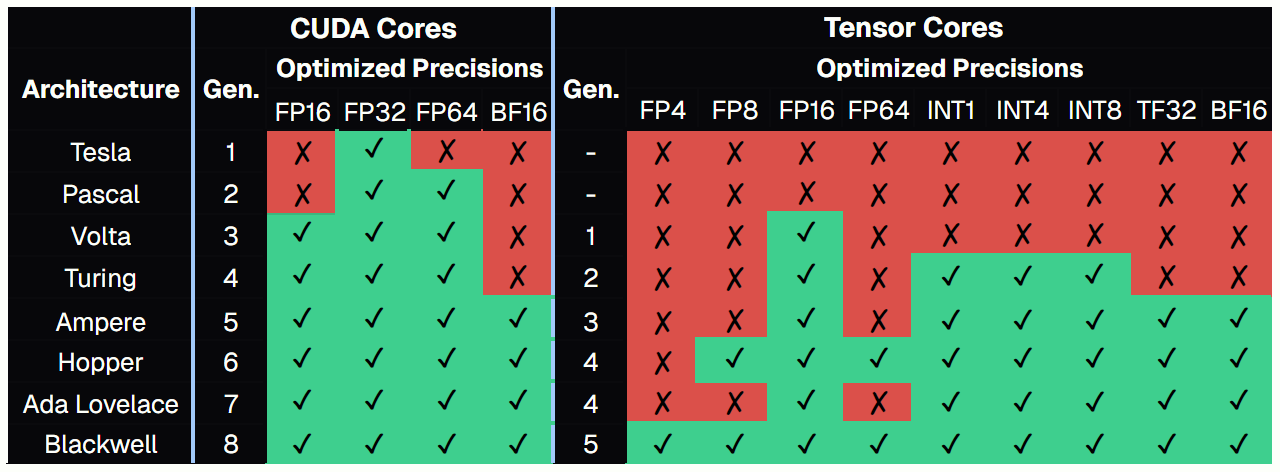
Optimized Precisions by Core Generations
Each Tensor and CUDA core generation adds new data types for specific AI workloads. Optimized precisions are formats with dedicated hardware acceleration, which deliver higher throughput and better efficiency than general-purpose compute paths.
Do More CUDA Cores Equal Better Performance?
More CUDA Cores do not automatically mean better performance, and the misconception leads to poor hardware decisions.
CUDA Core count matters only if your workload can use all those cores effectively. Many applications hit bottlenecks elsewhere in the system before maxing out core utilization. Memory bandwidth, cache size, and architectural improvements often have bigger impacts on real-world performance.
The RTX 4080 often outperforms the RTX 3090 despite having fewer CUDA Cores. The 3090 has 10,496 CUDA Cores while the 4080 has 9,728. Regardless, the 4080 wins because it features newer Ada Lovelace architecture, higher clock speeds, and improved memory subsystem.
For AI workloads, Tensor Core count and memory capacity matter more than raw CUDA Core numbers. An A100 with 6,912 CUDA Cores will outperform an RTX 3090 with 10,496 CUDA Cores in deep learning tasks because of its 432 Tensor Cores and 80GB of HBM2e memory.
Five factors determine GPU performance:
- Memory bandwidth: How fast data moves between GPU memory and cores.
- Cache hierarchy: How well the GPU accesses frequently used data.
- Clock speeds: How fast individual cores operate.
- Architectural design: How well the GPU schedules and executes work.
- Memory capacity: Whether your dataset fits in GPU memory.
CUDA Programming: Writing Code for the GPU
CUDA is a platform, not a single language. You can write CUDA code in C, C++, and Fortran, with wrappers available for Python (PyCUDA) and Java. The core concept is the kernel, a function that runs on the GPU across many parallel threads.
The typical workflow starts on the host CPU and transfers data from system RAM to GPU VRAM. You then launch kernels that process that data in parallel and copy results back to the host. Libraries like cuDNN (NVIDIA's deep learning primitives) and cuBLAS (NVIDIA's linear algebra library) provide CUDA acceleration without raw GPU code.
CUDA Cores for AI and Machine Learning
CUDA Cores match the mathematical structure of machine learning. Neural network training repeats millions of similar calculations across data samples and model parameters, and CUDA Cores run thousands of them at once.
During neural network training, CUDA Cores accelerate several critical operations, including:
- Data preprocessing: Changing raw datasets into training-ready formats.
- Forward passes: Computing predictions through network layers.
- Gradient computation: Calculating how to update model weights.
- Inference serving: Processing user requests in production systems.
CUDA Cores also accelerate inference for real-time AI applications, including chatbots, image recognition systems, and recommendation engines.
Training state-of-the-art models requires thousands of CUDA Cores running for days or weeks, which is why cloud GPU access matters for AI development. Our blog covers strategies for optimizing AI workloads across GPU configurations.
Small teams and individual researchers can now rent the same parallel processing power that once required a tech giant's hardware budget.
CUDA Enabled GPUs
CUDA runs only on NVIDIA GPUs, across its three product lines: data center, workstation, and consumer cards. Data center GPUs like the A100 and H100 suit large-scale training. RTX workstation and consumer GPUs handle development, fine-tuning, and inference.
Cloud platforms let you test several CUDA-enabled GPUs quickly and match a configuration to your workload without buying hardware.
Thunder Compute for CUDA Workloads
Thunder Compute delivers the most cost-effective access to CUDA-powered GPUs in the cloud. It's built for developers who need serious computing power without traditional cloud complexity or pricing.
| GPU Model | VRAM | Hourly Price (USD) |
|---|---|---|
| NVIDIA RTX A6000 | 48 GB GDDR6 | $0.35 |
| NVIDIA A100 80GB | 80 GB HBM2e | $1.09 |
| NVIDIA L40 | 48 GB GDDR6 | $0.79 |
| NVIDIA L40S | 48 GB GDDR6 | $0.99 |
| NVIDIA H100 80GB | 80 GB HBM3 | $2.19 |
Thunder Compute suits CUDA workloads for four reasons:
- Instant deployment: Launch GPU instances in seconds, not minutes.
- Persistent storage: Your data and environment survive instance restarts.
- Hardware swapping: Change GPU types without losing your work.
- VS Code integration: Develop on-cloud GPUs as if they were local machines.
Every Thunder Compute instance ships with CUDA pre-installed and optimized. PyTorch, TensorFlow, and custom CUDA kernels all work out of the box, so you can focus on AI development instead of infrastructure management.
Hardware swapping sets Thunder Compute apart from traditional cloud providers. Start developing on an RTX A6000 with 10,752 CUDA Cores, then move to an H100 with 14,592 CUDA Cores for serious training. Your code, data, and environment stay exactly the same.
Thunder Compute also removes the usual cloud GPU pain points: no capacity shortages, no complex billing structures, no vendor lock-in. You pay only for what you use, with transparent per-hour pricing and the option to stop instances when you don't need them.
Last Thoughts on CUDA Cores
CUDA cores make GPU parallelism possible, but they only reach peak AI training performance alongside the right architecture, memory bandwidth, and Tensor Cores. Thunder Compute makes those GPUs available on demand, so you can pick the right CUDA-enabled card without an upfront hardware commitment.
FAQ
How many CUDA cores do I need for AI training?
The right CUDA core count depends on your workload and dataset size. A GPU with 2,000 to 3,000 CUDA Cores (like the NVIDIA T4) handles small experiments. Large-scale training benefits from an RTX 4090 or A100. Memory capacity and Tensor Cores usually matter more than raw core count.
What's the main difference between CUDA Cores and Tensor Cores for AI workloads?
CUDA Cores handle general parallel computing tasks like data preprocessing and activation functions. Tensor Cores specialize in the matrix multiplications that dominate neural network training. Both work together across a complete machine learning pipeline.
Why doesn't a GPU with more CUDA Cores always perform better?
CUDA core count is one factor among several in GPU performance. Memory bandwidth, cache hierarchy, clock speeds, and architectural design often have a larger impact on real-world throughput than raw core count.
How do I get started with CUDA development without buying expensive hardware?
Cloud GPU services like Thunder Compute provide CUDA instances from $0.35/hr for an RTX A6000, with the A100 80GB at $1.09/hr and the H100 at $2.19/hr. You can test GPU configurations without upfront hardware costs.
Do GPUs have cores?
Yes. A single NVIDIA GPU contains thousands of CUDA Cores, the physical processing units built into the chip. A CPU has far fewer cores, each optimized for complex sequential tasks rather than simple parallel operations.
What do CUDA cores do?
CUDA Cores execute basic arithmetic operations: addition, multiplication, and floating-point calculations. CUDA Cores run massive numbers of simple, repetitive operations in parallel. In AI training, they accelerate data preprocessing, forward passes, gradient computation, and inference serving.
What does CUDA stand for?
CUDA stands for Compute Unified Device Architecture, NVIDIA's proprietary parallel computing platform and toolkit. Developers use CUDA to write code that programs CUDA cores, tapping thousands of them in parallel to accelerate compute-heavy tasks.
Can I run CUDA on AMD GPUs?
No. CUDA runs only on NVIDIA GPUs, including data center cards like the A100 and H100, RTX workstation cards, and consumer GeForce cards. AMD GPUs use a separate compute stack instead.
What programming languages support CUDA?
CUDA supports C, C++, and Fortran directly, with wrappers available for Python (PyCUDA) and Java. Libraries such as cuDNN and cuBLAS provide CUDA acceleration without writing raw GPU kernels.
What is a Streaming Multiprocessor in an NVIDIA GPU?
A Streaming Multiprocessor (SM) is the hardware block that holds CUDA cores and schedules their work. Each SM groups threads into warps of 32 and issues instructions to them together, which keeps thousands of CUDA cores busy.