Fine-tuning LLMs used to mean waiting hours for a run to finish and watching GPU memory creep toward the limit. Unsloth AI makes fine-tuning faster and leaner without sacrificing output quality.
This guide walks through what Unsloth is, how to install it, and how to run your first fine-tuning job. It also covers Unsloth Studio for those who prefer a no-code interface and looks at how Thunder Compute can remove the hardware barrier entirely.
What Is Unsloth
Unsloth is an open-source fine-tuning library for LLMs. It's built to make supervised fine-tuning faster and more memory-efficient. The library rewrites the core attention and backpropagation kernels by hand in Triton, bypassing much of the overhead that frameworks like Hugging Face Transformers introduce when running on NVIDIA GPUs.
In practice, Unsloth reports that fine-tuning runs 2x–5x faster than a standard Hugging Face + bitsandbytes setup and uses 50–70% less VRAM, depending on the model and configuration, allowing models to run on a single consumer-grade or mid-tier GPU.
Unsloth supports a wide range of popular open-weight models out of the box (including the Llama series, Mistral, Phi, Gemma, and Qwen3). Making it straightforward to fine-tune those models with the same efficient pipeline.
Key Features of the Unsloth Fine-Tuning Tool
Before jumping into installation, it helps to understand what the Unsloth fine-tuning tool actually provides:
- Custom Triton kernels: Hand-written kernels for attention, RoPE embeddings, cross-entropy loss, and backpropagation that are faster than compiled alternatives.
- 4-bit and 16-bit quantization: Native support for QLoRA (4-bit) and LoRA (16-bit) fine-tuning without quality degradation.
- Long context support: Extended context windows without proportional memory increases.
- GGUF and vLLM export: Trained adapters can be exported directly to GGUF for local inference with llama.cpp or merged for deployment with vLLM.
- Broad model coverage: Pre-patched support for the most widely used open-weight model families.
- Unsloth Studio: A visual, notebook-style interface for users who prefer not to write code.
Unsloth Studio: The No-Code Option
Unsloth Studio is a browser-based interface that wraps the same underlying engine as the Python library. It provides visual workflows to upload datasets, select base models, configur training hyperparameters, and monitor runs.
Studio is particularly useful for teams that want to experiment with fine-tuning without committing to a full Python environment, or for anyone who want to tinker quickly on dataset and hyperparameter choices. It connects to the same model hub and supports the same export formats as the CLI-based workflow.
If you are comfortable with Python, the library offers more flexibility. If you want results without setup overhead, Studio is a reasonable starting point.
System Requirements
Unsloth runs best on NVIDIA GPUs with CUDA support. However, Intel GPUs work and CPU-only is supported for light inference.
| Component | Minimum | Recommended |
|---|---|---|
| VRAM | 8GB | 16–24GB |
| CUDA | 11.8 | 12.1+ |
| Python | 3.9 | 3.10 or 3.11 |
| PyTorch | 2.0 | 2.2+ |
| OS | Linux | Ubuntu 20.04 / 22.04 |
AMD and Apple MLX should be supported soon.
How to Install Unsloth
Installation varies slightly depending on your CUDA version. The recommended approach uses conda to manage the environment cleanly.
To skip installation, create a Thunder Compute instance using the Unsloth template and access the data center GPUs.
Step 1: Create a Conda Environment
If not installed on your computer, first you need to get Conda.
conda create --name unsloth_env python=3.11 -y
conda activate unsloth_env
Step 2: Install PyTorch with CUDA
In your terminal run nvidia-smi to find your CUDA version and replace cu121 to match (cu118, cu121, or cu124).
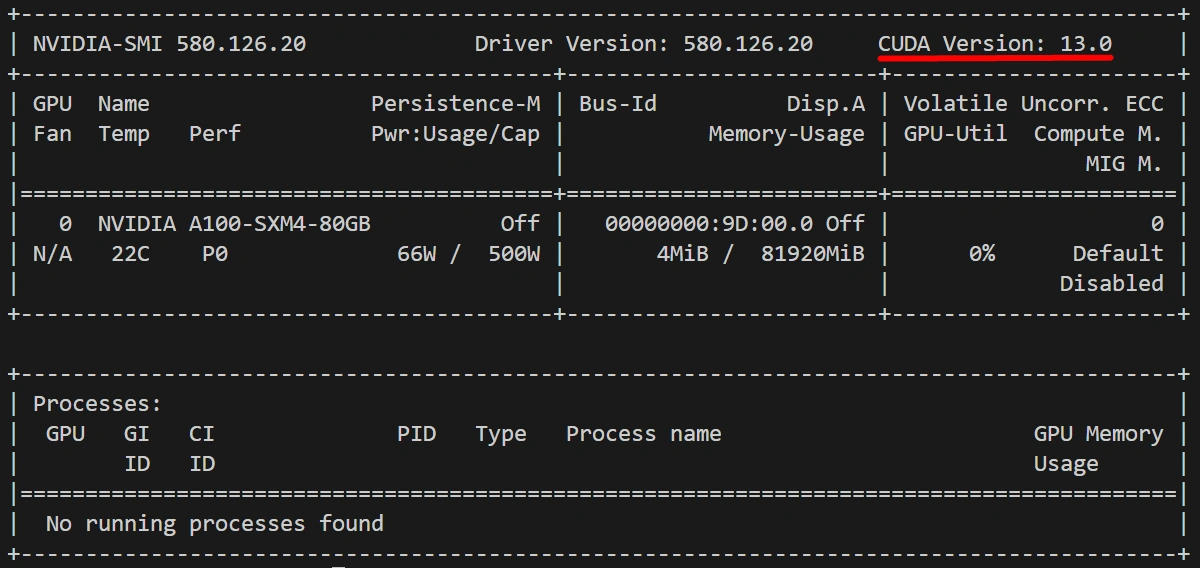
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
Step 3: Install Unsloth
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps "trl<0.9.0" peft accelerate bitsandbytes
Alternatively, for a stable release from PyPI:
pip install unsloth
To verify the installation:
python -c "import unsloth; print(unsloth.__version__)"
Troubleshooting Unsloth
| Issue | Likely Cause | Fix |
|---|---|---|
| CUDA out of memory | Batch size too large | Reduce per_device_train_batch_size to 1 |
triton import error |
Triton not installed or wrong version | pip install triton==2.1.0 |
| Slow training despite Unsloth | PyTorch version mismatch | Reinstall PyTorch matching your CUDA version |
| Model not found on Hugging Face | Private or gated repo | Run huggingface-cli login and accept model terms |
| NaN loss after a few steps | Learning rate too high | Reduce learning_rate to 1e-4 or lower |
Run Unsloth on Cloud GPUs with Thunder Compute
The biggest practical barrier to Unsloth fine-tuning is hardware. A capable GPU with 16GB+ VRAM is ideal for anything beyond the smallest models, and consumer cards in that range are expensive. Cloud GPUs solve that, but most providers require navigating infrastructure configuration before you can run a single training step.
Thunder Compute provides on-demand GPU instances accessible through VSCode, a CLI, or as a web app. You get a remote GPU that behaves like a local machine: install packages, run scripts, move files.
Thunder Compute offers a pre-built Unsloth Studio template that has the environment already configured. CUDA, PyTorch, and Unsloth are installed and tested. You select the template, choose your GPU, and within minutes you're loading your model and dataset.
For teams running multiple fine-tuning experiments, the per-minute billing model means you only pay for active compute time. Spin up an instance for a training run, export your model, and shut it down. There is no idle cost between experiments.
Final Thoughts on How to Run Unsloth
Unsloth removes two of the biggest obstacles to LLM fine-tuning: slow training and high VRAM consumption. Whether you run it locally, on Colab, or through a cloud provider like Thunder Compute, the setup is straightforward and the performance gains are immediate. Pick your base model, prepare your dataset, and let Unsloth handle the rest.
If hardware is still holding you back, Thunder Compute is the fastest way to get moving. Spin up a pre-configured Unsloth instance in minutes, run your fine-tuning job on a capable cloud GPU, and shut it down when you're done.
Now that you know how to accelerate your training with Unsloth, find the perfect model by checking out our guide to the best open-source LLMs.
FAQ
Does Unsloth work on Google Colab?
Yes. Unsloth provides Colab-specific installation instructions and notebooks. Free Colab GPUs (T4) can run smaller models in 4-bit mode, though VRAM limits restrict which models are feasible.
Can Unsloth fine-tune models larger than 70B parameters?
Yes, but it requires multiple GPUs or very aggressive quantization. Models above 30B parameters in 4-bit mode require at least 24 GB of VRAM. Multi-GPU support in Unsloth is available but less mature than single-GPU setups.
Is the Unsloth fine-tuning tool free to use?
The open-source version is free under the Apache 2.0 license. Unsloth also offers a paid Pro tier with additional features and support.
How does Unsloth compare to Hugging Face TRL without Unsloth patches?
Unsloth consistently benchmarks at 1.5–2.5x faster training speed with 40–70% lower VRAM usage on equivalent hardware, based on the team's published benchmarks. Results vary by model architecture and batch configuration.
What export formats does Unsloth support?
GGUF (for llama.cpp), merged 16-bit weights, VLLM-compatible checkpoints, and standard Hugging Face safetensors format.