Runpod, CoreWeave, and Thunder Compute all target AI workloads, but they serve very different users. Runpod focuses on flexible self-serve GPU access, CoreWeave focuses on large-scale infrastructure, and Thunder Compute focuses on low-cost, easy-to-use GPU instance.
Here's a real-world comparison of these platforms (and what we think is the best platform overall) on cost, usability, and performance to help you choose the right GPU cloud.
Breakdown
Deployment
- RunPod uses Docker-based pods.
- CoreWeave is Kubernetes-native and best suited for teams with DevOps experience.
- Thunder Compute offers one-click VS Code integration and hardware swapping without extra fees.
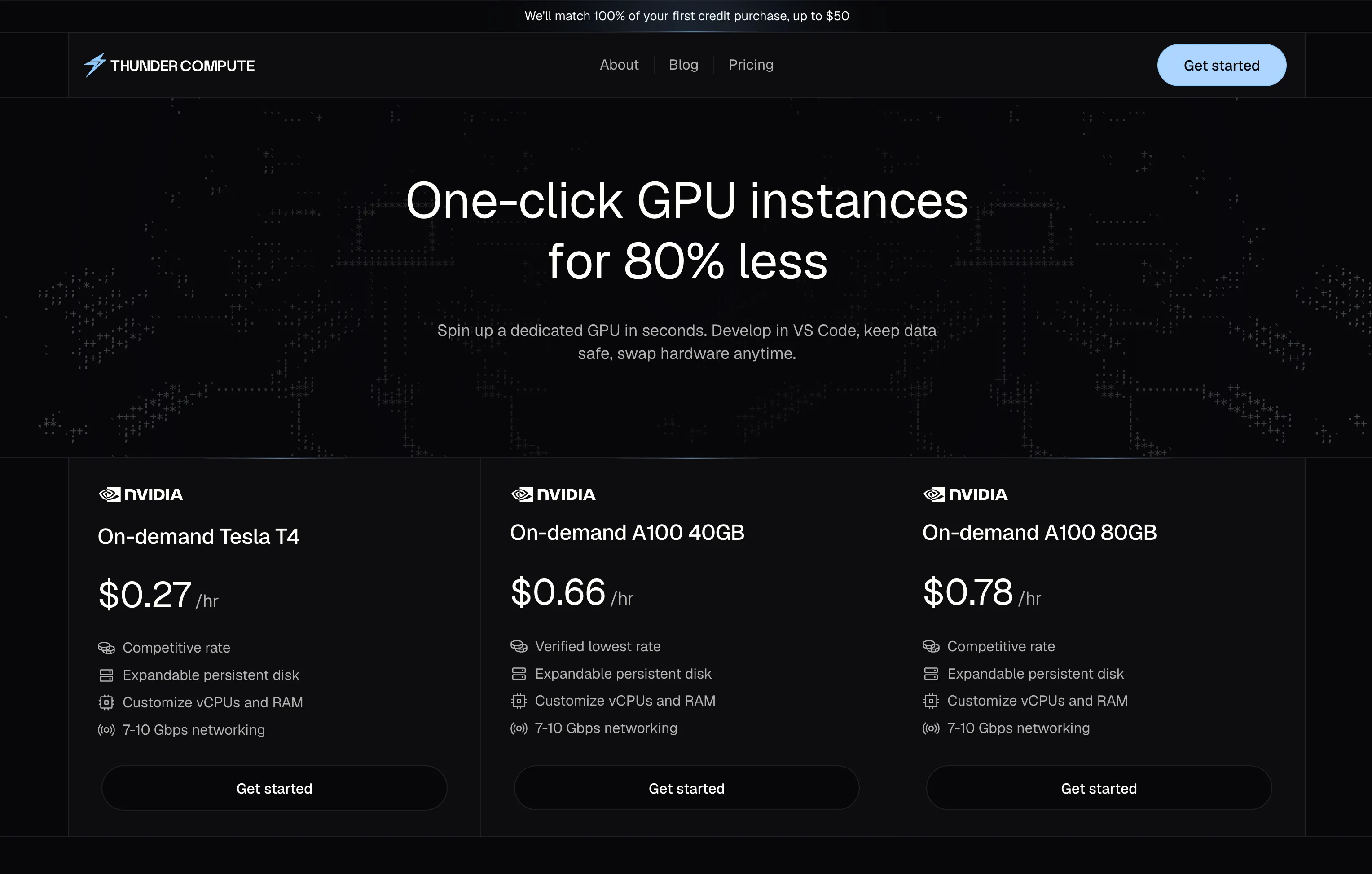
Pricing - Thunder Compute costs about 22% less than RunPod ($1.09/hr vs. $1.39/hr for A100 80GB).
Pricing Comparison
The cost differences between these providers reveal stark contrasts in their target markets and value propositions. Let's break down the actual numbers you'll pay for common GPU instances.
| GPU Type | RunPod | CoreWeave | Thunder Compute |
|---|---|---|---|
| RTX A6000 | $0.49/hr | N/A | $0.35/hour |
| A100 80GB | $1.39/hr | $2.50/hour | $1.09/hour |
| H100 80GB | $2.89/hr | $2.70/hour | $2.19/hour |
RunPod's per-second billing sounds flexible. But here's the catch: hourly rates add up quickly for longer training jobs. Their H100 instances are listed at $2.89/hr, meaning a 24-hour training run costs $69.36, while the same workload on Thunder Compute costs $52.56.
CoreWeave's enterprise focus is evident in its pricing approach. Most competitive rates require reserved capacity discussions and volume commitments, which create uncertainty for budget planning and make CoreWeave impractical for smaller projects or variable workloads.
The savings compound over time. A team running continuous development workloads could save thousands monthly by switching to Thunder Compute.
Always factor in hidden expenses, they're everywhere. RunPod charges separately for persistent storage and premium support. CoreWeave's enterprise model often includes consulting fees and minimum commitments.
Thunder Compute delivers transparent pricing without extra complexity around the core developer workflow. See our A100 GPU pricing analysis for more context on market pricing.
What CoreWeave Does and Its Approach
CoreWeave is an enterprise-focused GPU cloud provider for large AI deployments and teams that need high-performance infrastructure. It emphasizes Kubernetes-native operations, large-scale orchestration, and advanced networking for distributed workloads.
Using CoreWeave effectively requires more technical expertise than a self-serve developer cloud. Teams often work through container orchestration, YAML-based infrastructure, and platform engineering workflows instead of simple one-click instance launches.
CoreWeave is a strong fit for organizations that already operate production clusters and want infrastructure designed for scale. Smaller teams can still use CoreWeave, but the platform is generally less approachable for fast development.
The platform also highlights high-performance networking such as InfiniBand, which is only relevant for distributed training and multi-node jobs.
What Runpod Does and Its Approach
Runpod is a flexible cloud GPU platform built for developers, ML specialists, and AI startups that want self-serve access to GPUs without a traditional enterprise procurement process. Runpod combines marketplace-style variety with per-second billing and multiple product models.
Runpod lets users launch containerized GPU pods across many regions. Runpod also supports serverless workflows, which makes the platform appealing for teams that want both training environments and inference deployment options in one ecosystem.
Every Runpod pod runs in an isolated container with root access, which gives users plenty of control. That flexibility is helpful, but it also means Runpod usually works best for users who are comfortable with images, environments, and container-based workflows.
Billing is per second or per hour, with no volume minimums, reservations, or negotiation required. Community Cloud pods are especially budget-friendly, making Runpod ideal for experimentation, rapid development, or short-term jobs.
What Thunder Compute Does and Its Approach
Thunder Compute focuses on simplicity and cost-effectiveness for developers, researchers, and startups doing AI and ML work. It provides on-demand GPU instances with one-click deployment, native IDE integrations, and persistent storage in a workflow that is easier to adopt than a container-heavy or Kubernetes-heavy setup.
Instead of requiring users to build around infrastructure tooling first, Thunder Compute emphasizes fast starts and direct coding workflows. Users can launch an instance and work in familiar tools such as VS Code, Cursor, and Windsurf.
Thunder Compute also includes hardware swapping, snapshots, and start-stop workflows that help users preserve their environment while controlling compute spend. Those features are especially useful for iterative research and development work.
Thunder Compute provides root access and supports common AI and ML workflows without asking smaller teams to operate like platform engineering organizations. The result is a simpler path from idea to experiment to production-ready work.
The cheapest cloud GPU providers comparison shows how often lower prices come with trade-offs elsewhere. Thunder Compute is positioned around low pricing plus a cleaner workflow.
Performance and Reliability Considerations
Infrastructure reliability and performance differ greatly across these providers due to their hardware management philosophies and target markets.
RunPod's performance varies with tier selection. "Community" instances offer crowdsourced hardware at competitive pricing but can be subject to inconsistent performance, variable availability, and occasional interruptions. Their "Secure Cloud" tier is more stable, but at a higher hourly cost. Multi-region support enables broad geographic selection.
RunPod's spot instance model can offer significant cost savings, but with an increased risk of interruptions, posing challenges for long-running jobs unless rigorous checkpointing is implemented.
CoreWeave delivers enterprise-grade uptime, robust networking (including InfiniBand), and reliable cluster management, making it a strong fit for high-availability production workloads. Access to advanced features typically requires enterprise contracts, and Kubernetes-native orchestration, while powerful, introduces potential configuration issues that only skilled DevOps can resolve.
Thunder Compute ensures consistent performance by combining software-driven orchestration with dedicated hardware and 7-10 Gbps networking, offering rapid data transfer and robust checkpointing. Users can change GPU specs, keep persistent environments, and scale resources for larger jobs without switching between separate instance classes.
The Runpod alternatives landscape shows a common pattern: simpler platforms often win on usability, while enterprise platforms win on orchestration depth. Thunder Compute tries to keep the workflow simple without giving up the hardware that serious AI work needs.
Thunder Compute as the Better Fit for Most Teams
For most indie developers, researchers, and startups, Thunder Compute is the better fit because it combines lower pricing with a simpler workflow. Runpod offers more deployment variety, and CoreWeave offers deeper infrastructure primitives, but many teams do not need that extra complexity.
Runpod is a reasonable option when users want marketplace variety, serverless products, or more self-directed environment control. CoreWeave is a reasonable option when teams already have Kubernetes and platform engineering capability. Thunder Compute is the best fit when teams want to get into a GPU quickly and keep costs predictable.
The pricing gap is significant. Thunder Compute lists A100 80GB at $1.09/hr versus $1.39/hr on Runpod and about $2.50/hr on CoreWeave. Thunder Compute also lists H100 80GB at $2.19/hr versus $2.89/hr on Runpod and about $6.16/hr on CoreWeave.
For developers, researchers, and startups that want reliable GPU access without enterprise procurement friction or extra infrastructure overhead, Thunder Compute is the most practical option in this comparison.
Final Thoughts
The right GPU cloud depends on how much infrastructure complexity your team wants to own. CoreWeave is strongest when orchestration depth matters most. Runpod is strongest when flexibility and deployment variety matter most. Thunder Compute is strongest when price, simplicity, and fast developer workflows matter most.
Teams that want to spend more time building models and less time managing infrastructure should start with Thunder Compute.
FAQ
What's the main difference between Runpod and CoreWeave pricing?
Runpod offers a self-serve, developer-centric model with per-second billing. As of June 2026, an A100 80GB costs approximately $1.39/hr in their Community Cloud. CoreWeave is geared toward enterprise infrastructure, often requiring 8-GPU configurations. Their A100 80GB pricing is roughly $2.50/hr per GPU within these larger nodes, though they offer significant discounts for multi-year reserved contracts.
How does Thunder Compute support different workload stages?
Thunder Compute supports different workload stages through hardware swapping, persistent storage, snapshots, and scalable GPU choices. You can start with a smaller instance and move to A100 or H100 capacity when the job needs more memory or throughput, without choosing between separate instance classes.
Can I switch GPU types without losing my development environment?
Yes, Thunder Compute features "Hardware Swapping," allowing you to scale from a lower-tier GPU like an RTX A6000 to an H100 without rebuilding your workspace. In contrast, providers like Runpod and CoreWeave typically require creating a new instance or a fresh deployment workflow to change hardware.
Why does CoreWeave require more infrastructure expertise?
CoreWeave is built on Kubernetes-native infrastructure, which is highly powerful but requires DevOps or platform engineering knowledge to manage. Runpod provides a simpler container-based UI, while Thunder Compute targets a friction-free experience with native IDE integration, such as its VS Code extension, allowing developers to code without managing complex clusters.