This post covers the best TensorDock alternatives right now, ranked by what actually matters: GPU availability, on-demand pricing, and time to first workload. Pricing is current as of June 2026.
What Happened to TensorDock
TensorDock was acquired by Voltage Park in March 2025. The founder, Jonathon Lei, moved into a new role at the parent company, and new leadership was installed. In the months that followed, TensorDock's own uptime monitor recorded near-zero availability: roughly 6% in October 2025 and 0% in November 2025. Recovery has been partial and uneven since then.
The issue is structural. TensorDock is a marketplace that connects customers to independent GPU hosts. When ownership changes and leadership turns over, those host relationships can erode. If hosts pull their hardware, the dashboard goes empty regardless of whether the website loads.
TensorDock's own FAQ acknowledges the problem: "The GPUs I need are not available! Contact support, and we can ask our hosts to add additional stock."
The Core Problem with GPU Marketplace Models
Not every GPU provider owns its hardware. In a marketplace model, independent hosts list their machines on the platform, set their own availability windows, and can withdraw at any time.
This drives pricing competition, but it also means availability can disappear overnight and quality varies by host. Vast.ai operates the same way, as did TensorDock before its acquisition.
Cloud GPU Pricing Compared
Here is where pricing stands across the main TensorDock alternatives as of June 2026. All figures are published on-demand rates
| Provider | A100 80GB / hr | H100 80GB / hr |
|---|---|---|
| Thunder Compute | $0.78 | $1.38 |
| Vast.ai | ~$1.94 (variable)1 | ~$2.58 (variable)1 |
| RunPod | $1.39 | $2.89 |
| Hyperstack | $1.35 | $1.90 |
| TensorDock | $0.902 | $1.992 |
| Lambda Labs | $2.79 | $3.99 |
| Modal | $2.50 | $3.95 |
| CoreWeave | $2.70 | $6.16 |
The Best TensorDock Alternatives
Thunder Compute: Lowest On-Demand Pricing with a Developer-First Experience
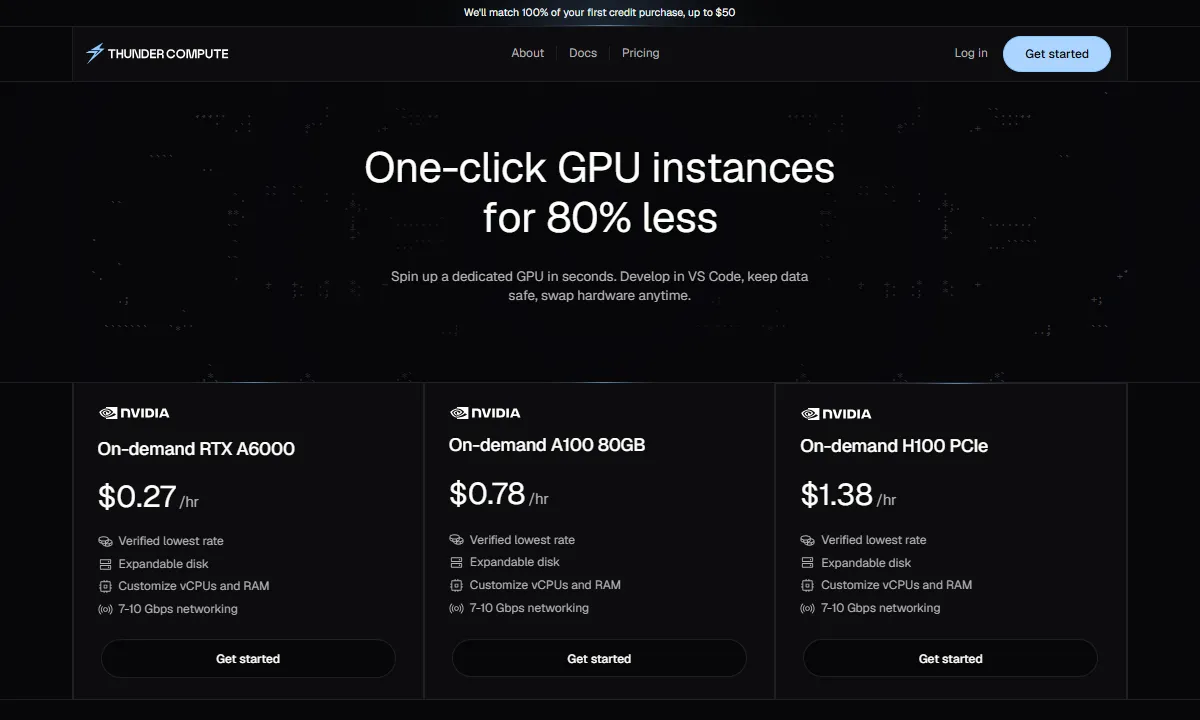
Thunder Compute runs managed GPU infrastructure with A100 80GB instances at $0.78/hr and H100 PCIe at $1.38/hr. Both are verified on-demand rates with no bidding, no spot risk, and no marketplace hosts to go offline.
Thunder is built around the workflow developers actually use. VS Code and Cursor extensions let you connect directly to a GPU instance from your IDE without configuring SSH. Persistent storage means your environment, checkpoints, and data survive instance restarts, and you can swap GPU types without rebuilding from scratch.
Instances spin up in under 30 seconds with per-minute billing. There are no egress fees and no hidden charges.
RunPod: The Closest Alternative to TensorDock's Original Model
RunPod offers a similar range of GPU types, on-demand pod pricing, and a web interface that will feel familiar to TensorDock users.
Its strongest differentiator is serverless: RunPod's serverless GPUs scale to zero when idle, cutting the cost of keeping an inference endpoint warm. The pre-built template library also speeds up environment setup.
The trade-off is a hybrid infrastructure model. Some nodes are RunPod-owned; others are community-contributed. Availability and performance can vary between the two pools. For critical workloads, you need to use RunPod's dedicated infrastructure (Security Cloud).
Vast.ai: Marketplace Flexibility, More Reliability Risk
Vast.ai is a fully decentralized marketplace where anyone with spare GPU hardware can list capacity. Hosts range from professional data centers to individuals renting out a gaming rig.
Vast.ai can be cheap for some consumer GPUs, but the June 2026 pricing reference lists A100 80GB at about $1.94/hr and H100 80GB at about $2.58/hr.
For experimental workloads or short jobs with checkpointing enabled, Vast.ai is a legitimate option. For production inference or multi-day training runs, the unpredictability is a real operational cost. Vast.ai carries the same structural risks that contributed to TensorDock's issues.
Lambda: Best for Managed Environments and Research Workflows
Lambda has a strong reputation among researchers and ML engineers who want a managed environment without infrastructure overhead. Lambda's strength is consistency and polish: Jupyter environments work reliably, and the platform is opinionated in ways that reduce setup friction.
The persistent knock on Lambda is availability. GPU stock, particularly H100s, sells out frequently, and there is no spot or preemptible fallback. If you need GPUs on a deadline, Lambda can leave you waiting. It is best suited for structured training workflows where reproducibility matters more than cost.
Modal: Best for Python-Native Serverless GPU Workloads

Modal takes a different approach entirely. Instead of renting a persistent VM, you write Python functions decorated with Modal's SDK and the platform provisions GPUs only while those functions run. Idle costs drop to zero, and cold starts are fast.
This works well for inference pipelines and batch processing jobs. It is not a fit for interactive development, long training sessions, or workflows that need persistent state between runs.
If you were using TensorDock to host a Jupyter notebook or run week-long fine-tuning jobs, Modal will not replace that directly.
CoreWeave: Best for Enterprise-Scale Multi-GPU Clusters
CoreWeave's infrastructure is purpose-built for large multi-GPU workloads, with NVIDIA Quantum InfiniBand and SHARP in-network compute for inter-node communication, NVLink for intra-node GPU connectivity, and SLAs designed for enterprise customers. H100 pricing works out to around $6.16/GPU/hr normalized from their 8-GPU node pricing.
For most TensorDock users, CoreWeave is overkill. If your workload requires a 64-GPU cluster with low-latency interconnects and you need an SLA, CoreWeave is the right destination. Everyone else should start elsewhere.
Cheap A100 Cloud Options: How the Alternatives Stack Up
For most fine-tuning and inference workloads, an A100 80GB is a solid choice on cost. It can run 70B parameter models at INT8 quantization within its 80GB VRAM and is more widely available.
See Thunder Compute's full guide to the cheapest cloud GPU providers.
Which Alternative Is Right for Your Workload
The right TensorDock replacement depends on what you are building.
For cost-sensitive teams needing H100 or A100 access with predictable pricing and a strong developer experience, Thunder Compute is the straightforward answer. The VS Code integration removes SSH friction that compounds over weeks of development.
For teams that want the closest drop-in to TensorDock's original model with some reliability variance, RunPod is the best fit. Its serverless tier adds value for inference-heavy workloads.
For production-grade SLAs on large multi-GPU clusters, CoreWeave is the right destination. For Python-native batch workloads that fit a serverless model, Modal is worth a close look.
Last Thoughts on TensorDock Alternatives
TensorDock served a real need, but the combination of an acquisition, leadership turnover, and marketplace fragility has made it unreliable through much of 2025 and into 2026.
Thunder Compute offers pricing that beats TensorDock's rates on both A100 and H100, with dedicated infrastructure, VS Code integration, and persistent storage by default.
See Thunder Compute's current GPU pricing and spin up an instance today.
Frequently Asked Questions
Is TensorDock Still Working in 2026?
TensorDock's website loads, but GPU availability has been widely reported as empty or unresponsive since late 2025. TensorDock's own uptime monitor recorded near-zero availability in October and November 2025, following the Voltage Park acquisition. As of June 2026, the service status remains unclear. If you need GPUs now, use a provider with demonstrated current availability.
Why Is TensorDock Showing No GPUs Available?
TensorDock is a GPU marketplace: the hardware belongs to independent hosts, not TensorDock itself. If those hosts take their machines offline, the dashboard goes empty regardless of whether the website loads. The transition following the Voltage Park acquisition appears to have disrupted the host supply network.
What Is the Cheapest TensorDock Alternative with Working GPUs?
Thunder Compute offers A100 80GB at $0.78/hr and H100 PCIe at $1.38/hr, both on-demand with no minimum commitment and no egress fees. These rates are lower than TensorDock's GPU-only listed prices even before accounting for TensorDock's availability problems. Vast.ai can be cheaper on some consumer GPU listings, but its marketplace model carries the same structural risks that affected TensorDock.
Does TensorDock's Acquisition by Voltage Park Change Anything?
Voltage Park acquired TensorDock in March 2025 with stated plans to expand GPU availability and improve infrastructure. In practice, the transition coincided with the most severe service disruptions in TensorDock's history. Whether the platform recovers under new ownership is an open question. Teams that need reliable compute today should not wait on that outcome.
Can I Get H100 Access Without a Long-Term Commitment?
Yes. Thunder Compute, RunPod, and Lambda Labs all offer on-demand H100 access with no contracts or reserved instance requirements. Thunder Compute's H100 PCIe starts at $1.38/hr with per-minute billing and no egress fees, making it the most cost-effective on-demand option among providers with owned infrastructure.