Prerequisite: Ensure your Thunder Compute account is ready. If not, start with our Quickstart Guide.
Step 1 — Create a Cost‑Effective Development‑Mode GPU Instance
Launch an 80 GB A100 instance (large enough to host the full 120 B model):- GPU: A100 80 GB
- vCPUs: 4
- Storage: 200 GB (from the Ollama template)
The GPU, vCPU Count, and Mode (Development / Production), can be changed later if your requirements change, and the amount of storage can be increased if needed.For details on templates, see the Instance Templates guide.
Step 2 — Check Status and Connect
Verify that the instance is running, it can take a minute to spin up: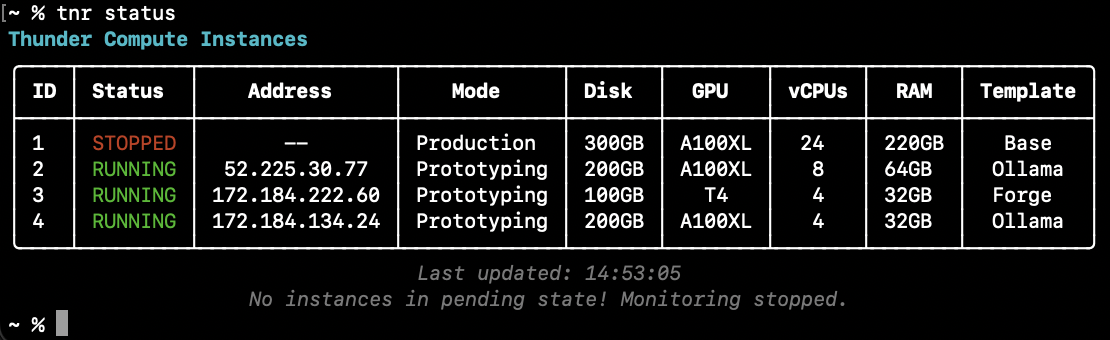
Step 3 — Start Ollama and Download the Model
Inside the instance, start Ollama (this also launches OpenWebUI and a Cloudflare tunnel):Tip: If you encounter issues, consult the troubleshooting guide.Give the UI about 60 seconds to finish loading.
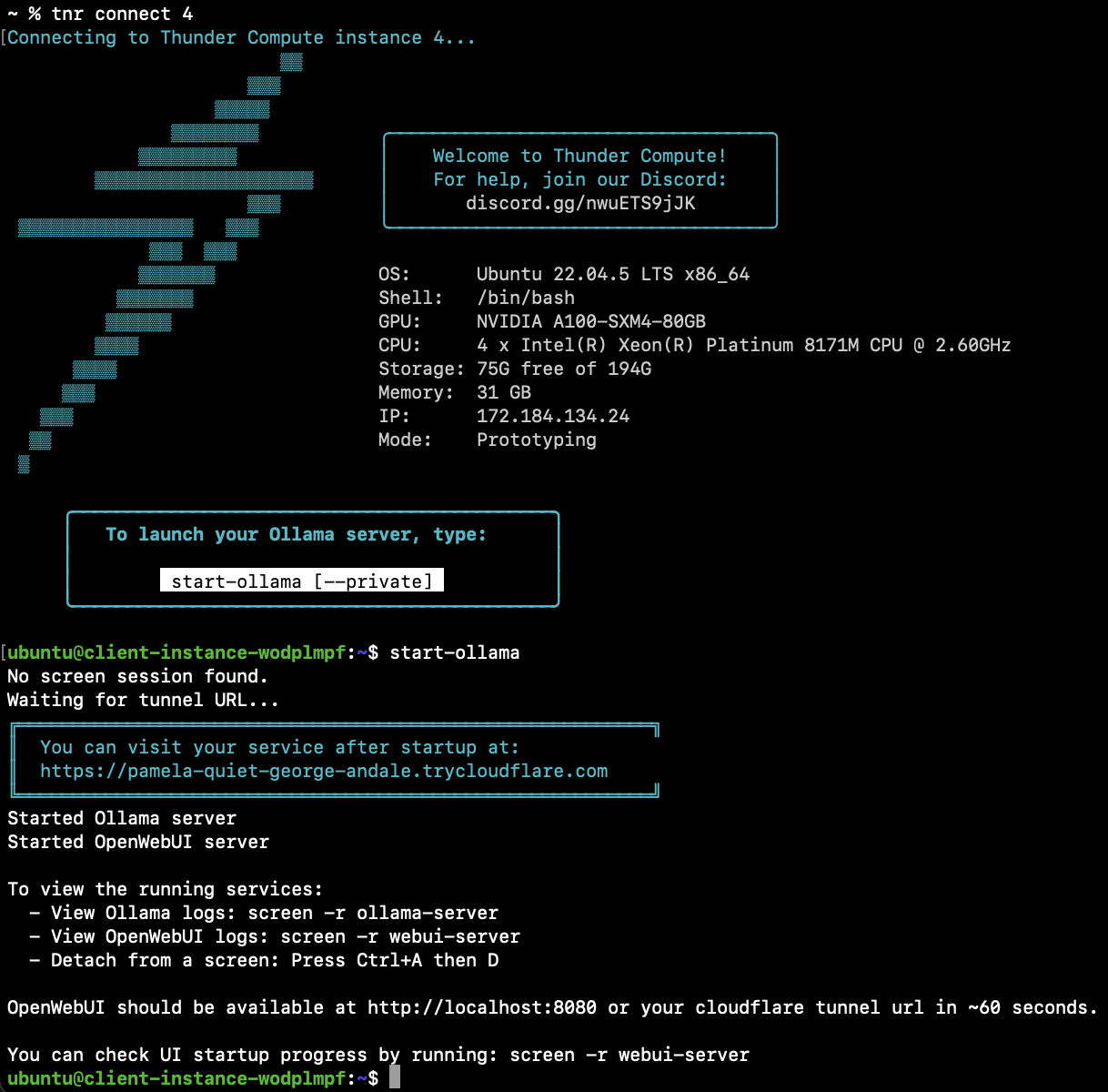
Step 4 — Access the Web UI and Select the Model
- Open the Open WebUI URL that
start-ollamaprints. It looks likehttps://<instance-id>-8080.thundercompute.net. - Choose gpt-oss:120b from the model dropdown.
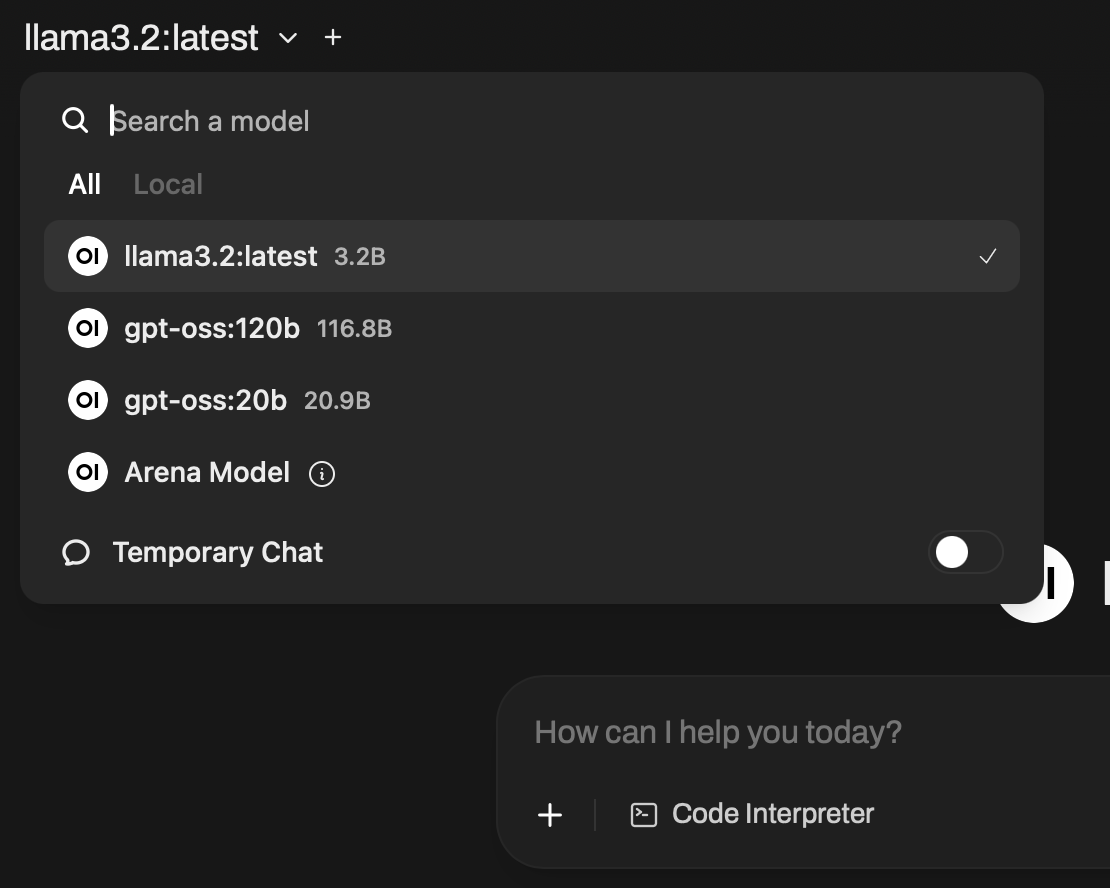
Step 5 — Run GPT‑OSS 120B
Enter a prompt in the web interface, for example:“Tell a tale of a seaman who found the treasure of the clouds by following the sound of thunder.”