Lambda is one of the most recognizable names in GPU cloud computing, and its pricing reflects that position. Before committing to Lambda's on-demand rates, it is worth knowing exactly what you are paying and what alternatives cost less.
This post covers Lambda's full GPU pricing, how it compares to Thunder Compute, and the key differences in developer experience that affect real workflows.
Key takeaways:
- Thunder Compute costs 45–61% less than Lambda across common GPU types.
- Both services bill per minute with no egress fees.
- Lambda's H100 SXM nodes are only available as 8-GPU configurations; single-GPU H100 access requires PCIe instances.
- Thunder Compute includes persistent storage and one-click IDE integration by default.
Looking at more than just Lambda? Explore Lambda alternatives including Runpod, Crusoe, Vast.ai, and more.
Lambda GPU Pricing (July 2026)
Lambda's on-demand pricing is listed per GPU per hour. H100 and A100 SXM instances are sold as 8-GPU nodes; per-GPU pricing is shown for comparison.
| GPU | VRAM | Config | Price/GPU/hr | Notes |
|---|---|---|---|---|
| NVIDIA B200 SXM6 | 180 GB | 8x only | $6.69 | Latest Blackwell architecture |
| NVIDIA H100 SXM | 80 GB | 8x only | $3.99 | NVLink + InfiniBand between nodes |
| NVIDIA H100 PCIe | 80 GB | 1x | $3.99 | Single-GPU H100 option |
| NVIDIA A100 SXM | 80 GB | 8x only | $2.79 | |
| NVIDIA A100 SXM | 40 GB | 8x only | $1.99 | |
| NVIDIA Tesla V100 | 16 GB | 8x only | $0.79 | Older architecture |
| Pricing sourced from lambda.ai/pricing Last update: July 13, 2026. | ||||
Lambda's H100 and A100 SXM instances are only sold in 8-GPU configurations. If you need two or four GPUs, you still pay for all eight. The only single-GPU H100 option is the PCIe variant at $3.99/hr.
Lambda also offers 1-Click Clusters starting at 16 GPUs for large-scale distributed training. These bill weekly with a two-week minimum commitment, making them a different product from on-demand instances.
Thunder Compute vs Lambda: Pricing Comparison
Thunder Compute offers A100 and H100 on-demand instances at substantially lower rates, with flexible GPU counts from 1x to 8x.
| GPU | Thunder Compute | Lambda | Savings |
|---|---|---|---|
| A100 80GB (1x) | $1.09/hr | $2.79/hr 1 | 61% |
| H100 80GB (1x) | $2.19/hr | $3.99/hr (PCIe) | 45% |
| 1 Lambda's A100 80GB is sold as an 8x SXM node at $2.79/GPU/hr. There is no single A100 80GB option on Lambda. | |||
| Thunder Compute pricing from thundercompute.com/pricing. Lambda pricing from lambda.ai/pricing. Both verified July 2026. | |||
Both services bill per minute, so you are not paying for idle time. Thunder Compute's pricing also includes 100GB per GPU at no extra charge. Additional storage runs $0.03/100GB/hr while running; snapshots cost $0.05/GB/month.
Lambda: Enterprise AI Infrastructure
Lambda targets research institutions and enterprise teams that need large-scale training capacity. Their GPU lineup runs from the V100 through the latest B200.
Their cluster infrastructure uses 8x GPU SXM nodes with NVLink within each node and NVIDIA Quantum-2 InfiniBand networking between nodes, delivering 3200 Gbps of bandwidth per HGX B200 or H100 cluster. This setup is purpose-built for NVIDIA GPUDirect RDMA and distributed training workloads where inter-GPU bandwidth is the bottleneck.
Lambda instances come pre-configured with Ubuntu, TensorFlow, PyTorch, NVIDIA CUDA, and cuDNN through Lambda Stack, plus Jupyter and SSH access out of the box.
Lambda targets larger organizations and research institutions that need multi-GPU setups for substantial training workloads. Their messaging highlights enterprise-grade infrastructure and AI-specific tooling.
Thunder Compute: Developer-First GPU Access
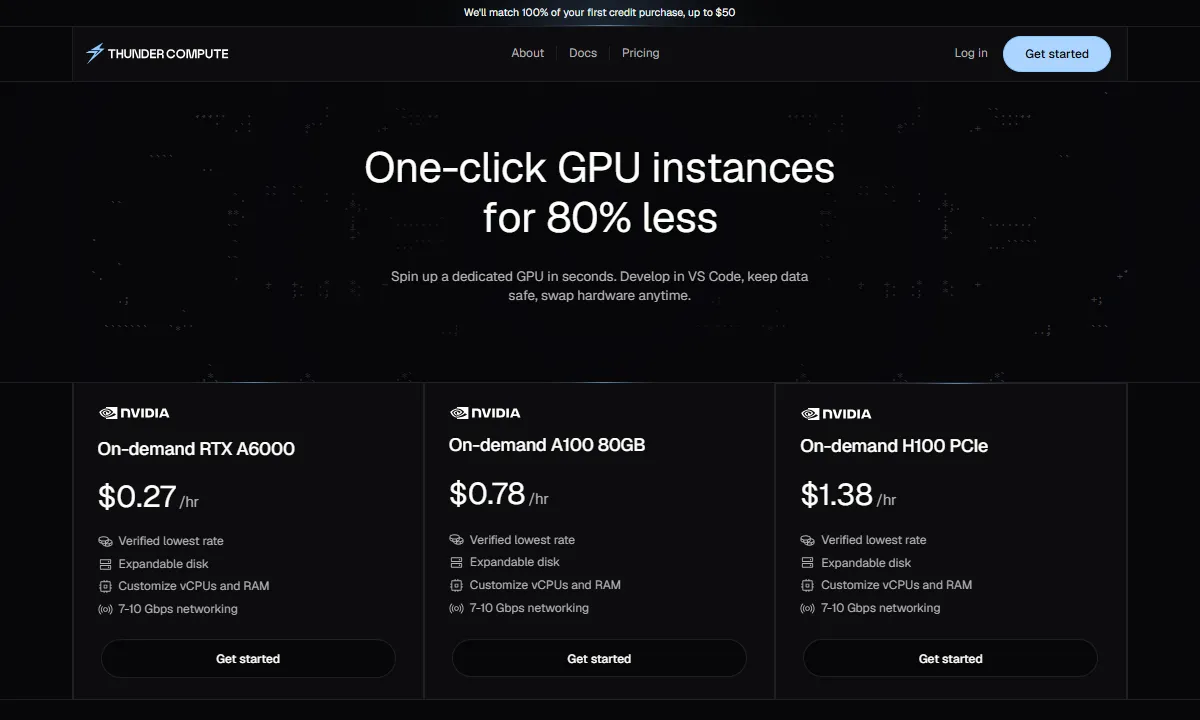
Thunder Compute supports RTX A6000, L40, A100 80GB, and H100 PCIe GPUs with 1x, 2x, 4x, and 8x configurations. Every instance includes persistent storage by default: your home directory and installed packages survive restarts with no manual setup. You can snapshot your instance at any point and restore it later, including when switching GPU configurations.
The VS Code, Cursor, and Windsurf extensions connect directly to a running instance. You can edit code, run notebooks, and manage files as if they were local, without SSH setup or driver configuration. Instances are also accessible via CLI, web console, and REST API.
Our approach focuses on software-driven GPU orchestration that allows ultra-low pricing while maintaining reliability and ease of use. Thunder Compute focuses on on-demand instances for startups, research, and development, running dedicated A100 hosts in U.S. data centers and letting you spin up an on-demand instance in 30 seconds.
Hardware and Infrastructure
Lambda excels at multi-node cluster infrastructure. For distributed training across 16 or more GPUs, InfiniBand networking and NVLink topology deliver interconnect performance that single-node setups cannot match. Lambda also supports NVIDIA GH200 Superchip and RTX 6000 Ada instances.
Thunder Compute supports up to 8x GPUs per node with 7 Gbps networking. For most AI workloads, including fine-tuning, inference, and single-model training, single-node performance is what matters. Thunder's per-GPU pricing is substantially lower for that tier.
Lambda is optimized for large coordinated training jobs across many nodes. Thunder Compute targets teams that want reliable, affordable GPU access at the single-node level.
Developer Experience
Lambda provides a solid baseline: Jupyter, SSH, a web terminal, and a REST API. Lambda Stack reduces environment setup time and the service is familiar to teams that have used it before.
Thunder Compute is built around IDE-first workflows. The VS Code, Cursor, and Windsurf extensions remove the context switch of browser-based development. Persistent storage means your environment is always ready for you. Instance specs (vCPU count, RAM, and storage) can be expanded without rebuilding.
When to Choose Each Provider
Thunder Compute suits individual researchers, small teams, and startups running experiments or fine-tuning jobs at the single-node level. It offers lower on-demand pricing, per-minute billing, and persistent storage with minimal setup.
Lambda suits teams that need multi-node clusters of 16 or more GPUs with InfiniBand networking, or organizations with enterprise procurement and support requirements.
For most AI development, including model training, fine-tuning, inference, and experimentation, single-node performance on either platform is equivalent. The 45–61% cost gap in Thunder's favor adds up quickly over time.
Last Thoughts on Lambda GPU Pricing
The pricing difference between Lambda and Thunder Compute is 45% on H100 and 61% on A100 80GB for equivalent on-demand access. Lambda remains the right choice for large-scale distributed training with InfiniBand. For everything else, Thunder Compute delivers the same GPU hardware at a lower price with persistent storage and IDE integration included.
FAQ
How much does Lambda charge for H100 GPUs?
Lambda charges $3.99/GPU/hr for H100 SXM (8x nodes only) and $3.99/hr for single-GPU H100 PCIe. Thunder Compute offers H100 PCIe at $2.19/hr, about 45% less.
Which is cheaper for A100 GPUs: Lambda or Thunder Compute?
Thunder Compute is cheaper: A100 80GB at $1.09/hr versus Lambda's $2.79/GPU/hr for the A100 SXM 80GB (8x node). That is a 61% difference. Moreover, Lambda has no single-GPU A100 80GB option.
How does billing work on Thunder Compute vs Lambda?
Both bill per minute with no egress fees. You only pay while instances are running.
Does Thunder Compute support multi-GPU training like Lambda?
Yes. Thunder Compute supports 1x, 2x, 4x, and 8x configurations. Lambda's SXM nodes are 8x only, so you cannot rent 2 or 4 SXM GPUs without paying for the full node.
Which GPU cloud is better for VS Code users?
Thunder Compute. It offers one-click extensions for VS Code, Cursor, and Windsurf with zero SSH setup. Lambda provides Jupyter and SSH access but no native IDE extension support.
When should I choose Lambda over Thunder Compute?
Choose Lambda for multi-node clusters of 16 or more GPUs with InfiniBand. For single-node workloads, Thunder Compute's lower pricing is the better fit.
What storage does Thunder Compute include with GPU instances?
Every instance includes 100GB per GPU at no extra charge. Additional storage runs $0.03/100GB/hr while running; snapshots cost $0.05/GB/month.
Does Lambda offer spot instances?
No. Lambda has no spot or preemptible GPU pricing. Every instance is billed at the full on-demand rate.