RunPod's on-demand A100 80GB lists at $1.39/hr and H100 PCIe at $2.89/hr. That is fine for short jobs, but it adds up quickly once you are running multi-hour training runs or serving live inference traffic. Several alternatives undercut RunPod on price, improve on reliability, or offer capabilities RunPod does not.
Below are ten RunPod alternatives compared on GPU pricing, developer experience, and workload fit.
Why Teams Look for RunPod Alternatives
RunPod built a strong position as a flexible, affordable GPU marketplace. But several constraints push teams to evaluate other options.
Community Cloud reliability. RunPod's lower-priced tier draws from a distributed network of independent GPU hosts. RunPod's own terms of service make no warranty that these services will meet uptime requirements or be available without interruption. For production inference APIs or long training runs, this variability is a real risk.
H100 availability. During peak demand periods, popular H100 configurations sell out. Teams with unpredictable compute needs sometimes find themselves refreshing availability rather than training.
No native IDE integration. RunPod offers SSH, Jupyter, and a web terminal through Pods. It has no native extensions for VS Code, Cursor, or Windsurf, which adds friction for teams whose workflow lives in an IDE.
Limited EU presence. RunPod's global footprint is strong, but European data residency for GDPR compliance is less straightforward than with providers that operate dedicated EU data centers.
Quick Comparison: A100 and H100 Pricing
Rates are on-demand list prices per GPU per hour.
| Provider | A100 80GB ($/hr) | H100 80GB ($/hr) | Best For |
|---|---|---|---|
| Thunder Compute | $1.09 | $2.19 | Lowest managed price, IDE-first workflow |
| Vast.ai 1 | $1.94 | $2.01 | Marketplace pricing, checkpoint-friendly jobs |
| Hyperstack | $1.40 | $2.60 | Enterprise performance, EU availability |
| Google Colab | ~$1.50 2 | N/A | Interactive notebooks, education |
| Crusoe Cloud | $1.65 | $3.90 | Managed infrastructure, sustainability focus |
| Vultr | $2.40 | N/A | Global cloud ecosystem, 32+ regions |
| CoreWeave3 | ~$2.50 | ~$6.16 | InfiniBand clusters, enterprise training |
| Lambda | $2.79 | $3.99 | Managed ML environment, research labs |
| Paperspace | $3.18 | $5.95 | Jupyter notebooks, polished UX |
| Azure | ~$4.41 | N/A | Enterprise compliance benchmark |
| 1 Vast.ai marketplace pricing varies by host. 2 Google Colab uses Compute Units (~13-15 CUs/hr for A100 at $9.99/100 CUs). 3 CoreWeave pricing normalized from public 8-GPU node rates Last update: July 14, 2026. | |||
1. Thunder Compute
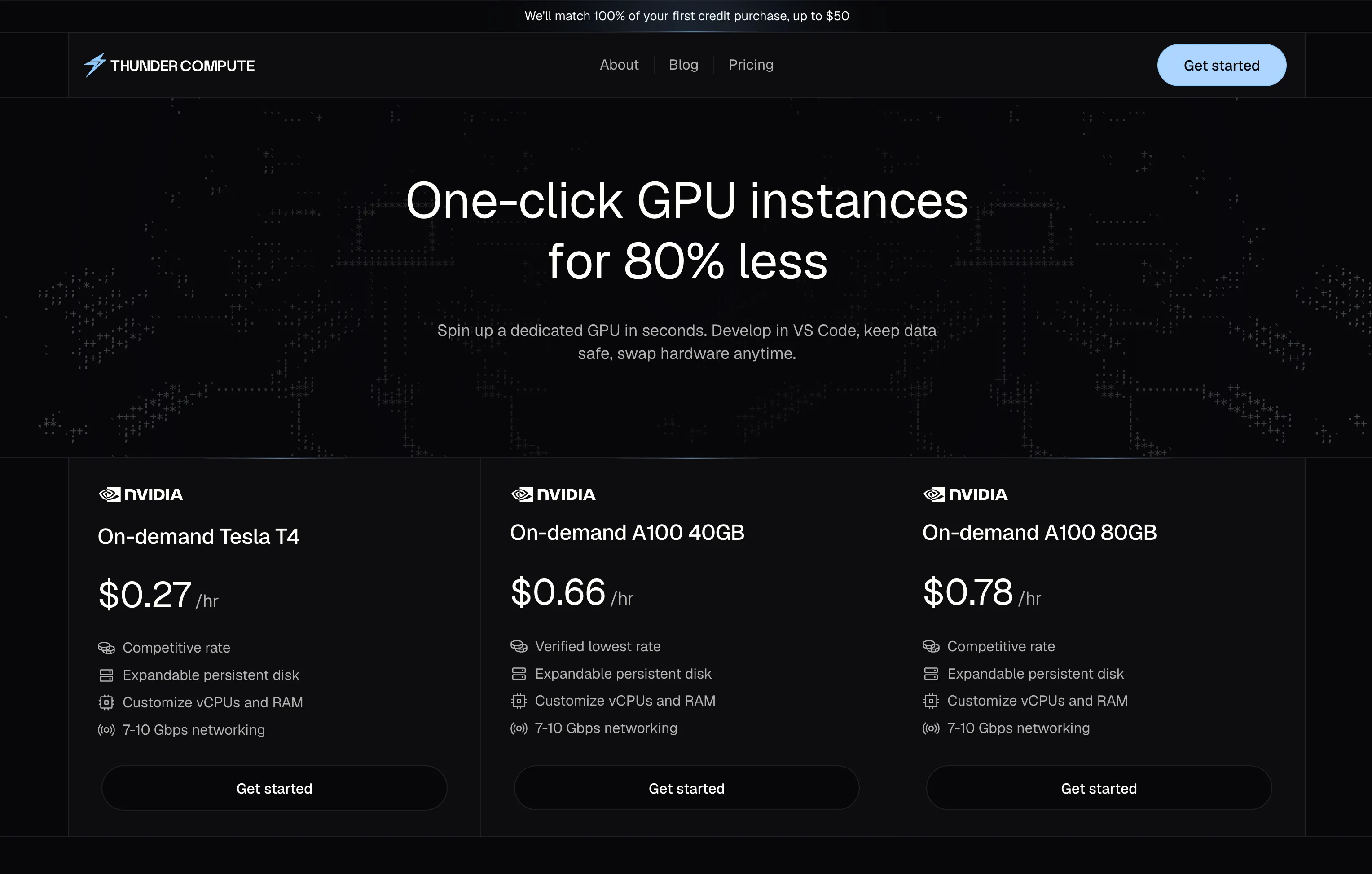
A100 80GB runs $1.09/hr and H100 PCIe runs $2.19/hr, both on-demand, billed per minute, and with no egress fees.
Every instance includes 100GB per GPU at no extra charge. Your home directory and installed packages survive restarts without any configuration. Snapshots for long-term storage cost $0.05/GB/month and let you save your full environment state before switching GPU configurations.
One-click extensions for VS Code, Cursor, and Windsurf connect directly to a running instance. Instances also support the CLI, web console, MCP server, and REST API. US university students get $20 in free credit on signup with a .edu email, usable on A6000 and L40 GPUs.
Account hoops: Email signup and credit card. No wait-list.
Best for: Solo researchers, startups, and ML engineers who want the lowest managed A100/H100 rate with IDE-first development and persistent storage included.
2. Vast.ai
Vast.ai is a peer-to-peer marketplace where independent GPU hosts list spare capacity. A100 80GB instances appear around $1.94/hr and H100 around $2.01/hr, making it a low-cost option for teams willing to manage the trade-offs.
Host quality varies significantly. Filtering for hosts with high uptime scores, verified hardware, and long platform tenure reduces risk, but a marketplace model will never match managed infrastructure consistency. Nodes can disappear mid-run with minimal notice.
Account hoops: None. Test a small workload before committing to long runs.
Best for: Budget-conscious researchers running non-critical, checkpoint-friendly training jobs.
3. Hyperstack
Hyperstack is a managed GPU cloud focused on enterprise performance and European availability. A100 80GB starts at $1.40/hr and H100 PCIe on-demand at $2.60/hr, with spot VM options for additional savings and an AI Studio for one-click model deployment.
The platform emphasizes sustainable infrastructure and offers on-demand Kubernetes alongside standard GPU instances.
Account hoops: Fast self-service signup. No enterprise contracts required for on-demand access.
Best for: Developers who need reliable, EU-available GPU infrastructure and care about sustainable compute.
4. Google Colab
Google Colab is a browser-based notebook environment that offers GPU access through a Compute Unit (CU) pricing model. A100 80GB sessions cost roughly $1.30–$1.50/hr equivalent (around 13–15 CUs/hr at $9.99/100 CUs), though pricing varies by session type and plan tier.
Colab's trade-offs: 12-hour session caps on standard tiers, automated idle timeouts, and no persistent instance between sessions. It works best for rapid development, interactive research, and education, not sustained training runs.
Account hoops: Google account required. Pro and Pro+ plans available for longer sessions.
Best for: Interactive development, education, and quick experiments that don't require persistent storage.
For a full comparison, read RunPod vs Google Colab Pro.
5. Lambda
Lambda is one of the most established managed GPU clouds, with Lambda Stack shipping Ubuntu, PyTorch, TensorFlow, CUDA, and cuDNN pre-configured. A100 80GB on-demand runs $2.79/hr and H100 PCIe at $3.99/hr.
Lambda's main limitation is availability: H100 inventory sells out during peak demand, and A100 and H100 SXM instances are only available as 8x nodes. There is no single-GPU A100 SXM option.
Account hoops: Instant signup; occasional wait-lists during demand spikes.
Best for: Research labs and teams that want a polished, pre-configured ML environment and are comfortable with Lambda's pricing.
6. Crusoe Cloud
Crusoe is a managed alternative to Lambda with public pricing. A100 80GB starts at $1.65/hr and H100 at $3.90/hr. Crusoe's infrastructure was originally built around stranded natural gas capture and has since expanded into grid-connected facilities with a broader energy mix. Spot instances are available for checkpoint-friendly workloads.
Account hoops: Join a short wait-list if inventory is tight.
Best for: Production workloads where uptime and sustainability reporting matter more than the lowest price.
7. CoreWeave
CoreWeave is purpose-built for large-scale distributed training, with InfiniBand networking between nodes and Kubernetes-native infrastructure. A100 80GB runs around $2.50/hr normalized from public 8-GPU node pricing; H100 on-demand is approximately $6.16/hr.
For teams running distributed training on 16 or more GPUs where interconnect bandwidth materially affects throughput, CoreWeave is one of the few providers that can deliver. The trade-off is accessibility: access approval takes a few business days and most large-cluster configurations require contracts.
Account hoops: Access approval required; can take a few business days.
Best for: Teams running large multi-GPU distributed training jobs that need InfiniBand and enterprise SLAs.
8. Vultr
Vultr provides GPU instances across 32+ global locations with a consistent, virtualized environment. A100 80GB Cloud GPU instances run $2.40/hr. Vultr sits between specialist GPU clouds and the big hyperscalers, with managed Kubernetes and S3-compatible object storage alongside GPU compute.
Account hoops: Standard cloud signup; may require identity verification for new accounts.
Best for: Teams that need GPU access alongside other cloud infrastructure in a single provider.
9. Paperspace
Paperspace, now part of DigitalOcean, offers strong Jupyter integration and a polished UI suited to teams new to GPU cloud. A100 80GB on-demand runs $3.18/hr and H100 at $5.95/hr. The Gradient platform and pre-configured ML environments reduce setup friction, but the per-GPU cost is the highest on this list outside of Azure.
Account hoops: Credit card signup; fraud checks are stricter than some competitors.
Best for: Users who want a polished UI and do not mind paying a small premium.
10. Azure

Azure is included as an enterprise benchmark, not a practical recommendation for most GPU compute workloads. GPU instances run approximately $4.41/hr for A100 configurations. Azure offers deep Microsoft ecosystem integration, enterprise compliance certifications, and global availability, but at prices that are hard to justify against specialist providers.
Account hoops: Complex subscription tiers and quota requests.
Best for: Organizations already heavily invested in the Microsoft ecosystem that need GPU access within existing Azure infrastructure.
Serverless GPU Alternatives
Teams looking to replace RunPod Serverless specifically should also evaluate Modal and Baseten. Both are purpose-built for serverless GPU inference and offer better developer experience than RunPod Serverless for variable-traffic workloads.
Modal is a Python-native platform where you decorate functions with GPU requirements and Modal handles scaling, containers, and billing. It charges per second of active compute time with automatic scale-to-zero, effective at roughly $2.50/hr for A100 and $3.95/hr for H100 converted to hourly. Baseten targets production model serving APIs with managed vLLM and TensorRT integration. Neither is suited for sustained training jobs, but both are stronger choices than RunPod Serverless for inference workloads.
How to Choose
- Lowest managed on-demand A100/H100 price: Thunder Compute. A100 at $1.09/hr, H100 at $2.19/hr, persistent storage included.
- Low-cost marketplace option, non-critical workloads: Vast.ai. Marketplace pricing with trade-offs in host reliability.
- Serverless inference that scales to zero: Modal or Baseten.
- Enterprise performance with EU availability: Hyperstack. On-demand A100 at $1.40/hr and H100 PCIe at $2.60/hr.
- Large multi-node distributed training: CoreWeave or Lambda. InfiniBand interconnect, enterprise SLAs.
- EU data residency: Nebius or Crusoe. Both offer infrastructure outside US-only regions.
- Jupyter-first, new to GPU cloud: Paperspace. Highest per-GPU cost but lowest setup friction.
- Global cloud ecosystem alongside GPUs: Vultr. 32+ regions, managed Kubernetes, S3 storage.
Last Thoughts on RunPod Alternatives
RunPod is a solid starting point, but the GPU cloud market has enough strong alternatives that "good enough" rarely is. For most AI training and development, Thunder Compute offers a simpler and lower-cost path: managed infrastructure, persistent storage included, and one-click IDE integration at the lowest on-demand A100 and H100 rates available. For everything else, the How to Choose section above maps your specific constraint to the right provider.
What is the cheapest RunPod alternative for A100 GPUs?
Thunder Compute at $1.09/hr for A100 80GB is the lowest managed rate, versus RunPod at $1.39/hr. Vast.ai marketplace pricing can go lower, with trade-offs in host reliability and variable bandwidth fees.
Is Vast.ai reliable for GPU compute?
Vast.ai offers the lowest marketplace prices, but host reliability varies. Nodes may disappear mid-run. Best for checkpoint-friendly batch jobs, not production inference or long uninterrupted training.
Which RunPod alternatives have the best GPU availability?
Thunder Compute and Lambda maintain strong A100 and H100 inventory for on-demand single-node access. CoreWeave has large cluster availability but requires contracts.
Do I need to join a waitlist for RunPod alternatives?
Thunder Compute, Vast.ai, and Paperspace offer instant access with email and credit card. Lambda occasionally shows out-of-stock. CoreWeave requires access approval that can take a few business days.
Which RunPod alternative is best for EU data residency?
Nebius operates data centers in Europe with GDPR compliance. Crusoe also operates outside US-only data centers. Both are better positioned than RunPod for European data residency requirements.
How does Thunder Compute compare to RunPod on storage costs?
Thunder Compute includes 100GB per GPU at no extra charge. RunPod charges $0.07/GB/month for network volumes. For 500GB of storage, RunPod adds $35/month before any compute.
Can I use RunPod Docker images on Thunder Compute?
Thunder Compute supports standard SSH access and CUDA environments. Most workloads that run in Docker on RunPod can be adapted to Thunder Compute, though Thunder does not use RunPod's proprietary container format.