Tensor cores are one of the main reasons modern GPUs can efficiently run AI workloads. This guide explains what tensors are, how tensor cores work, and why they matter for training and deploying machine learning models.
Takeaways
- Tensor cores accelerate matrix operations.
- More tensor cores do not guarantee better performance. Memory, software, and workload design are equally important.
- Efficient scaling is critical to fully utilizing tensor core performance.
What Is a Tensor?
In computing, tensors are multi-dimensional arrays of numbers categorized by number of dimensions (also called rank):
- Scalars (0D): A single numeric value (e.g., a weight, bias, or temperature).
- Vectors (1D): An ordered list of numbers (e.g., coordinates, or a single data sample).
- Matrices (2D): A grid of numbers arranged in rows and columns, often used to represent datasets or perform transformations like matrix multiplication.
In machine learning, tensors are the primary way data is represented and processed. Inputs, weights, activations, and outputs in neural networks are all stored as tensors, often with multiple dimensions representing features such as batch size, channels, height, and width.
Understanding tensors is key to understand how modern GPUs accelerate AI workloads.
What Are NVIDIA Tensor Cores?
Tensor cores are specialized processing units in NVIDIA GPUs that accelerate matrix multiplications and accumulations.
These operations are at the core of deep learning workloads. Instead of handling calculations sequentially like traditional cores, tensor cores perform large matrix operations in parallel, dramatically increasing throughput.
Another feature of Tensor Cores is that they are optimized for mixed-precision computing This enables faster performance without significantly compromising accuracy, which makes them essential for AI training and inference.
Since being deployed in 2017, they have contributed the highest peak computational performance.
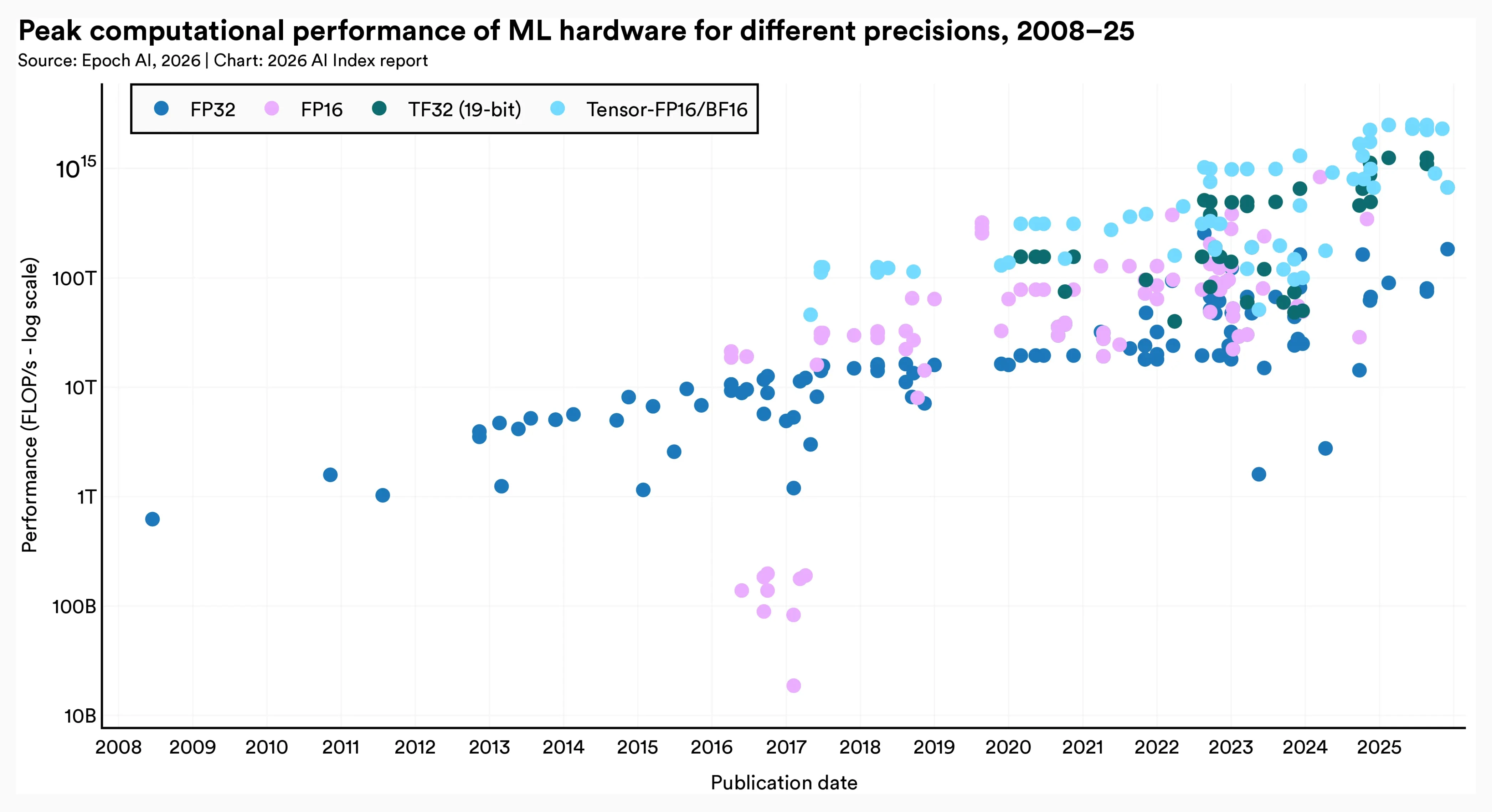 * AI Index Report: 1.2 Compute and Infrastructure
* AI Index Report: 1.2 Compute and Infrastructure
Overview Of Tensor Core Architecture
The primary function of tensor cores is to execute fused operations like matrix multiply-accumulate (MMA) in a single instruction, significantly improving throughput. This design makes them especially effective for deep learning, high-performance computing (HPC), and other tensor-heavy applications.
Tensor cores perform highly parallel matrix operations, processing multiple data elements simultaneously within a single clock cycle. Unlike traditional CUDA cores, which operate on scalar or vector instructions, tensor cores are optimized for small matrix tiles that can be composed into larger computations.
Tensor cores also support mixed-precision computation, including formats such as FP16, BF16, FP8, and INT8, allowing a balance between performance and numerical accuracy. By using lower-precision inputs with higher-precision accumulation, tensor cores can deliver substantial speedups without significant loss in model quality. This capability is critical in modern AI training and inference, where efficiency and scalability are key constraints.
Finally, tensor cores are tightly integrated with the GPU memory hierarchy, including shared memory and registers, to minimize data movement and maximize compute utilization. Efficient data feeding ensures that tensor cores remain saturated during execution, which is essential for achieving peak performance. As a result, software frameworks and compilers are designed to map tensor operations effectively onto this hardware.
Tensor Cores Vs CUDA Cores
Understanding tensor cores vs cuda cores is essential when evaluating GPU performance.
| Feature | Tensor Cores | CUDA Cores |
|---|---|---|
| Primary Function | Matrix operations (AI workloads) | General-purpose computation |
| Precision Modes | Mixed precision (FP16, BF16, FP8) | FP32, FP64 |
| Throughput | Extremely high for matrix math | Lower for tensor operations |
| Flexibility | Specialized | Highly flexible |
| Use Cases | AI training, inference | Physics, rendering, simulations |
CUDA cores handle a wide range of tasks, while tensor cores are highly specialized.
Optimized Precisions by Core Generations
Tensor and CUDA core generations introduce new data types for specific AI workloads. These “optimized” precisions correspond to formats that benefit from dedicated hardware acceleration, enabling higher throughput and better efficiency compared to general-purpose compute paths.
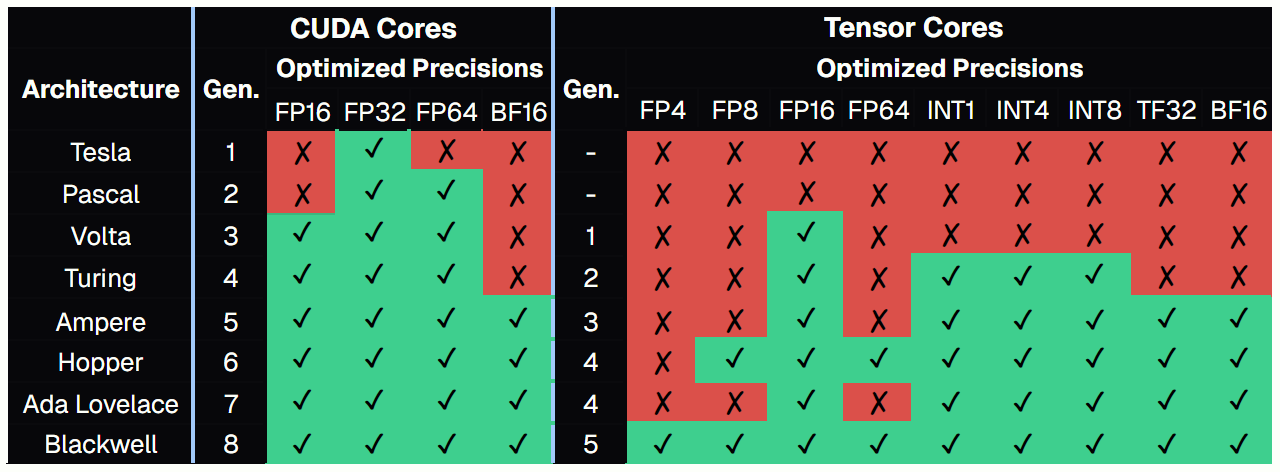
Do More Tensor Cores Equal Better AI Performance?
Not necessarily. While increasing tensor core count raises theoretical compute capacity, real-world performance depends heavily on system-level factors such as memory bandwidth, latency, and how efficiently data is fed into the compute units. Additionally, bottlenecks outside the cores themselves can limit achievable throughput.
Model architecture, size, and software optimization also play a critical role. Libraries like CUDA, cuDNN, and TensorRT are designed to map workloads efficiently onto tensor cores, but poorly optimized kernels or incompatible model structures can leave significant performance untapped. Precision formats further influence performance, as lower precision can increase speed but requires proper handling to maintain accuracy.
Additionally, more complexity is introduced when scaling across multiple GPUs. Communication overhead and parallelization efficiency can offset the benefits of having more tensor cores if not managed properly. In practice, balanced system design and optimized workloads matter as much as raw hardware specifications.
Tensor Cores For Deep Learning And Generative AI
Tensor cores are central to modern AI workloads, including:
- Training LLMs
- Image generation models
- Recommendation engines
These applications rely heavily on large-scale matrix multiplications. Executing fused matrix operations in a single step significantly increased throughput compared to traditional compute paths. This efficiency is what enables modern models to process massive datasets within practical timeframes.
As models continue to scale in size and complexity, the role of tensor cores becomes even more critical. Their performance is closely tied to the surrounding system, particularly high-bandwidth memory and fast interconnects that keep data flowing efficiently between compute units. Without this balance, even powerful tensor cores can sit underutilized, limiting overall system performance.
Tensor-Enabled GPUs: From Consumer To Enterprise
Tensor cores are widely available across all tiers (consumer, workstation and data center GPUs).
However, performance varies significantly depending on:
- Number of tensor cores
- Supported precision formats
- Memory capacity and bandwidth
Despite the wide availability of tensor cores, enterprise GPUs typically offer the highest throughput and are optimized for large-scale AI workloads.
Tensor Core Generations
Apart from expanding supported precisions, newer tensor core generations introduce architectural changes that improve efficiency, sparsity handling, and workload-specific optimizations.
| Architecture | GPU Examples | New Data Types Introduced | Key Features |
|---|---|---|---|
| Volta | V100 | FP16 | First-gen tensor cores |
| Turing | T4, RTX 20xx | INT8, INT4 | Integer inference acceleration |
| Ampere | A100, RTX 30xx | TF32, BF16 | Structured sparsity support |
| Hopper | H100 | FP8 | Transformer Engine, dynamic precision |
| Blackwell | B200, RTX 50xx | FP4 | Enhanced Transformer Engine |
This progression explains why newer GPUs can deliver performance gains beyond raw tensor core counts. Architectural improvements, not just core quantity, play a major role in real-world AI efficiency.
Thunder Compute For Tensor-Intensive Workloads
Tensor-heavy workloads require more than just powerful GPUs. Consistent access, predictable pricing, and scalable infrastructure all impact productivity.
Thunder Compute provide access to modern GPUs optimized for AI workloads, making it easier to experiment, train, and deploy models without long provisioning delays.
Final Thoughts On Tensor Cores
Tensor cores are a fundamental component of modern GPU architecture and a key driver of AI performance.
They enable the fast matrix computations required for deep learning, making them essential for training and deploying advanced models.
However, performance is not determined by tensor cores alone. Memory systems, software optimization, and workload design all play critical roles.
For anyone working with AI infrastructure, understanding tensor cores is essential when choosing the right hardware.