GPUs have powered deep learning for the last decade, but Google's Tensor Processing Units are now a serious contender. This comparison covers each chip, how they differ, their intended workloads, and where to rent them in 2026.
What Is a TPU?
TPU stands for Tensor Processing Unit. It's an application-specific integrated circuit (ASIC) designed by Google to accelerate tensor and matrix math, the core operations that power neural networks.
Unlike a general-purpose CPU or GPU, a TPU is specialized for machine learning data workflows. Its systolic array architecture is optimized for massive matrix and vector operations, drastically reducing memory access bottlenecks.

How Google Built TPUs for Deep Learning
TPUs were conceived in 2013, when Google projected that demand for neural network inference would double its datacenter footprint. Building enough CPU capacity for that load would have cost billions and years of construction. The solution was a purpose-built chip for matrix operations at a fraction of the power and cost.
Google went from concept to production and unveiled the first TPU in 2016. TPU v1 quietly powered Google Search, Photos, Translate, and YouTube. The key architectural decision was the systolic array: a grid of multiply-accumulate units that streams data through in a wave, reusing every intermediate result and reducing memory reads.
What Is a GPU?
A GPU, or Graphics Processing Unit, was originally designed to render pixels. Rendering requires computing thousands of polygons simultaneously, so GPUs were built for parallelism: thousands of small cores performing simple operations at once. In the late 2000s, researchers discovered that this architecture also excelled at training neural networks, giving GPUs a second career.
NVIDIA released CUDA in 2007, giving developers a programming model for GPU general computation. Researchers built entire ecosystems of libraries, frameworks, and tools on top of it. By the time deep learning exploded in the early 2010s, NVIDIA GPUs were already the accelerator of choice.
Why NVIDIA Dominates
NVIDIA's dominance comes down to two compounding advantages: hardware and ecosystem. Modern NVIDIA GPUs combine thousands of CUDA cores with dedicated Tensor Cores for mixed-precision matrix multiplication. PyTorch, the dominant AI framework, runs natively on NVIDIA GPUs with no translation layer required.
This combination has made NVIDIA GPUs the default choice for training, fine-tuning, and inference. Most frameworks, models, and workflows run on NVIDIA hardware out of the box.
Google's TPU Product Lines: Every Generation Explained
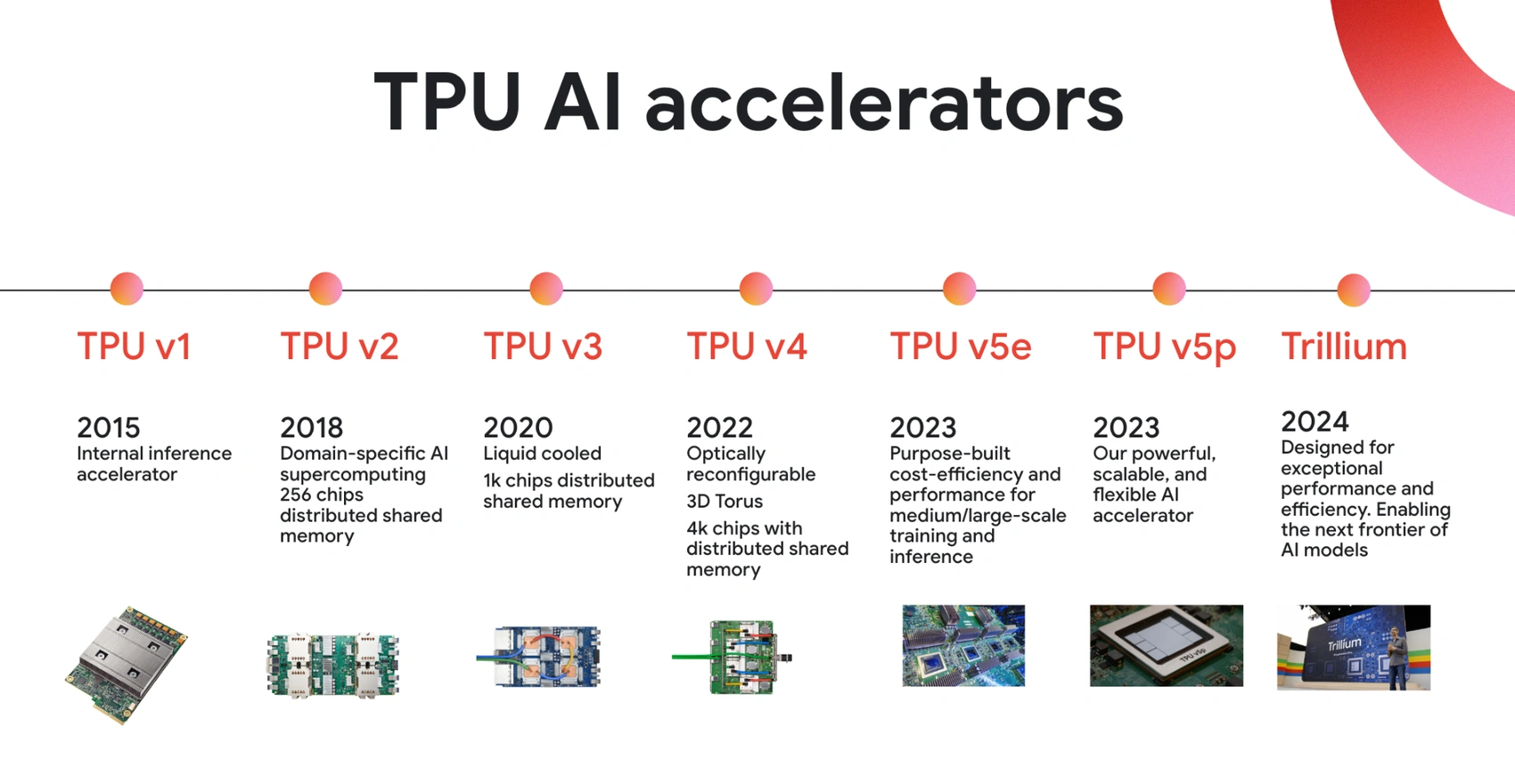
TPU v1 to v4: Early Generations
The first four generations of TPU established the foundation for everything that followed.
TPU v1 (2015) was an inference-only chip built on a 28-nanometer process, consuming 40W while delivering 92 trillion 8-bit operations per second. It plugged into standard servers via PCIe and was 15-30x faster than contemporary GPUs for inference, with 30-80x better operations per watt.
TPU v2 (2017) added training support by replacing 8-bit integer arrays with bfloat16 floating-point units, plus high-bandwidth memory and multi-chip pod scaling. It implemented 128×128 matrix multiplication units and 2D torus interconnects.
TPU v3 (2018) introduced liquid cooling and higher clock speeds.
TPU v4 (2021) upgraded to a 3D torus topology, cutting worst-case communication latency at large pod sizes. It became the chip behind many of Google's production models.
TPU v5e and v5p: Cost-Efficient Training
The v5 series introduced specialization within a single generation. The v5e is the cost-optimized variant: $1.20 per chip-hour on-demand, 393 trillion INT8 operations per second per chip, and 2.5x more throughput per dollar than TPU v4. The v5p is the high-performance variant for large-scale enterprise LLM training, priced at $4.20 per chip-hour and delivering 2.8x faster LLM training than v4 across 4,096-chip pods.
TPU v6e (Trillium): Performance Uplift
Trillium (TPU v6e) became generally available in Q4 2024 and represented a major jump in per-chip compute. Each chip delivers:
- ~918 BF16 TFLOPS (roughly 4x better than v5e)
- 32 GB of HBM with 1.6 TB/s memory bandwidth per chip
- 256×256 systolic array delivering 65,536 operations per clock cycle
- ~300W TDP, roughly half the H100's 700W
In an 8-chip configuration, Trillium delivers approximately 7,344 BF16 TFLOPS at roughly 300W TDP per chip, closely matching a quad-H100 NVL system's 6,682 TFLOPS at significantly lower power. It remains the cost-optimized production workhorse for large-scale inference on Google Cloud.
TPU v7 (Ironwood): Built for Inference

Ironwood (TPU v7) became generally available in late 2025 and is the most powerful custom silicon Google has built. Each chip delivers:
- 4,614 FP8 TFLOPS
- 192 GB of HBM3e with 7.37 TB/s of memory bandwidth
- 9.6 Tb/s ICI bandwidth to neighboring chips (1.2 TB/s bidirectional)
A full superpod integrates 9,216 chips for 42.5 exaFLOPS of FP8 compute, with 2x better perf/watt than Trillium and 4x better performance per chip than v6e.
TPU v8 (8t and 8i): Split for Training and Inference
Announced at Google Cloud Next in April 2026, the eighth generation marks the first time Google has fielded two distinct TPU architectures in a single generation (one optimized for training, one for inference). Both are co-designed with Google DeepMind, built on TSMC N3, and hosted on Google's Axion ARM-based CPUs. General availability is expected later in 2026.
TPU 8t (training) — designed by Broadcom, targeting large-scale model pre-training and fine-tuning:
- 12.6 FP4 PFLOPs per chip
- 216 GB HBM3e at 6,528 GB/s bandwidth
- 128 MB on-chip SRAM
- Superpods of 9,600 chips with 2 PB of shared HBM delivering 121 FP4 ExaFLOPs
- Virgo Network fabric scales to 134,000+ chips in a single non-blocking fabric
- 2.8x better training price-performance than Ironwood
TPU 8i (inference) — designed by MediaTek, targeting low-latency serving and agentic workloads:
- 10.1 FP4 PFLOPs per chip
- 288 GB HBM3e at 8,601 GB/s bandwidth
- 384 MB on-chip SRAM (3x Ironwood)
- Boardfly topology replacing the 3D torus, reducing worst-case network diameter by 56% for MoE model routing
- Collectives Acceleration Engine (CAE) cuts collective communication latency 5x
- 80% better inference price-performance than Ironwood
Both chips support JAX, PyTorch via TorchTPU (in preview), vLLM, and SGLang. TorchTPU enables native PyTorch on TPU 8 without the full PyTorch/XLA compilation overhead, though it remains in preview as of mid-2026.
TPU vs GPU: Key Differences Explained
Architecture: Systolic Arrays vs CUDA Cores
A TPU's systolic array is a grid of multiply-accumulate units that streams data in a single direction. Each unit receives values from its neighbor, computes a result, and passes it along, maximizing data reuse and reducing expensive memory reads.
A GPU uses CUDA cores organized into Streaming Multiprocessors (SMs), paired with Tensor Cores for matrix operations. This architecture handles branching, diverse data types (FP64, FP32, FP16, FP8, INT8), and non-uniform workloads that a systolic array struggles with. The trade-off is that general-purpose flexibility takes up chip space that could be used for raw matrix throughput.
Performance: Real-World Benchmarks
For large-batch matrix multiplication, TPUs hold a measurable advantage at pod scale. At pod level, TPU ICI interconnects scale to 9,216 chips, while GPU clusters rely on NVLink, NVSwitch, or InfiniBand, adding latency and configuration complexity.
For smaller workloads, single-model inference, or tasks with irregular compute patterns, GPUs typically win on raw latency. The H100 handles diverse batch sizes and data types without requiring tuning like TPUs.
Energy Efficiency: Performance Per Watt
Energy efficiency is where TPUs show a structural advantage. Trillium v6e runs at 300W TDP versus the H100's 700W, delivering 2-2.5x better performance per watt for transformer training. Ironwood extends that lead further with 2x better perf/watt than Trillium.
For organizations with sustainability targets or power-constrained data centers, this efficiency gap translates directly into lower operating costs.
Framework Support: TensorFlow, PyTorch, and JAX
GPUs natively support major frameworks: PyTorch, TensorFlow, JAX, and scientific computing libraries. Almost any open-source model or research codebase runs on a GPU without modification.
TPUs require code to pass through the XLA (Accelerated Linear Algebra) compiler, which integrates well with JAX and TensorFlow but needs an additional backend layer for PyTorch (PyTorch/XLA). Migrating a standard PyTorch codebase often means debugging compilation traces, restructuring loops, and handling host-device transfer patterns.
Ironwood (TPU v7) dropped TensorFlow support entirely. Only JAX and PyTorch are supported going forward.
Cost: Cloud Pricing and Total Cost of Ownership
On-demand pricing is only part of the cost story. TPU chips are rented exclusively on Google Cloud and range from $1.20 (v5e) to $4.20 (v5p). GPU pricing is more competitive: the H100 is available from AWS, Azure, GCP, Lambda, RunPod, CoreWeave, Thunder Compute, and many other providers, creating genuine competition.
Total cost should also include engineering time. Migrating a PyTorch workflow to TPUs is a major investment, and that cost must offset any savings to make TPUs economically attractive.
Google TPU vs NVIDIA GPU: A Head-to-Head Comparison
Google Ironwood TPU vs NVIDIA H100: How Do They Stack Up?
| Specification | Google Ironwood (TPU v7) | NVIDIA H100 SXM |
|---|---|---|
| Peak FP8 TFLOPS (per chip) | 4,614 | 3,958 |
| Memory per chip | 192 GB HBM3E | 80 GB HBM3 |
| Memory bandwidth | 7.37 TB/s | 3.35 TB/s |
| TDP (power draw) | ~1,000W (est.)1 | 700W |
| Max pod / cluster scale | 9,216 chips (ICI) | ~512 GPUs (NVLink / InfiniBand) |
| Framework support | JAX, PyTorch/XLA | PyTorch, TensorFlow, JAX, CUDA |
| Cloud access model | Google Cloud Platform | 40+ cloud providers |
Where Google TPUs Win
TPUs hold genuine advantages in specific, large-scale scenarios. For training very large transformer models at pod scale, TPU pods offer lower communication latency and higher memory bandwidth than equivalent GPU clusters. The ICI interconnect is a purpose-built fabric; GPU clusters depend on InfiniBand or NVLink, adding configuration complexity.
Ironwood's 2x better perf/watt also creates a real cost advantage for 24/7 hyperscale inference. Organizations deep in the Google Cloud ecosystem with JAX codebases additionally benefit from tight integration with Vertex AI, BigQuery, and Google's managed training infrastructure.
Where NVIDIA GPUs Win
NVIDIA GPUs win on flexibility, availability, and ecosystem. PyTorch runs natively on GPUs with no compiler layer. Any open-source checkpoint, any Hugging Face library, any research codebase works on an NVIDIA GPU out of the box.
GPUs are also available on-premises, on consumer hardware, and across dozens of cloud providers competing on price. That competition keeps GPU rates lower and gives developers leverage that does not exist with TPUs, which are locked to Google Cloud.
GPU vs TPU vs Other AI Accelerators
GPUs and TPUs dominate large-scale AI, but a few other accelerators appear in production and developer contexts often enough to be worth knowing.
CPU — Still the default for latency-sensitive single-request inference on small models, branching logic, and preprocessing pipelines. Modern server CPUs support AVX-512 instructions for modest AI acceleration. For training or large-model inference, CPUs are a bottleneck, not a solution.
NPU (Neural Processing Unit) — Embedded in consumer devices: Apple Silicon, Qualcomm Snapdragon, Intel Core Ultra, MediaTek Dimensity. NPUs are optimized for quantized (INT8/INT4) inference at very low power, ideal for on-device AI workloads. They are not cloud-accessible and not relevant for server-side training or large-model serving.
LPU (Language Processing Unit) — Pioneered by Groq (founded by ex-Google engineers who designed the original TPU). The LPU stores all model weights in on-chip SRAM rather than external HBM, eliminating memory-bandwidth bottlenecks during token generation. This delivers extremely fast token generation, but on-chip SRAM capacity limits which models can run. Best suited for fixed-model, high-throughput inference deployments.
Custom ASICs (Trainium, MTIA, Maia) — AWS Trainium 3, Meta MTIA, and Microsoft Maia 200 are hyperscaler-internal ASICs optimized for their own workloads. Like TPUs, they trade flexibility for efficiency at scale and are limited to their respective cloud providers. The custom ASIC market for AI is growing at 44.6% annually and could represent 45% of the AI chip market by 2028, but for developers outside those ecosystems they are not a practical option today.
For most developers, the decision still comes down to GPU vs TPU. The other accelerators occupy specific niches that rarely apply outside of hyperscale deployments or consumer edge devices.
When to Use a TPU vs a GPU
When to Use TPUs
- Training very large models (10B+ parameters) on Google Cloud with JAX or TensorFlow, with enough sustained chip-hours to justify committed-use discounts.
- High-volume batch inference at hyperscale (millions of requests per day), where v6e or Ironwood cost advantages compound over time.
- Workflows native to Google's AI ecosystem: Vertex AI, BigQuery ML, or the Gemini APIs.
- Transformer architectures with large, predictable matrix shapes that map cleanly to systolic arrays without extensive tuning.
Use Cases Where GPUs Win
GPUs are the better choice for the majority of AI practitioners:
- Any workflow built on PyTorch, including fine-tuning models, custom training loops, or production inference.
- Research and experimentation, where rapid iteration and framework flexibility are essential.
- Smaller teams who cannot absorb the engineering cost of migrating to XLA.
- On-premises deployments or multi-cloud strategies.
- Any workload that is not purely matrix-heavy.
Where to Rent TPUs (and GPUs): Cloud Provider Comparison
TPUs are available exclusively through Google Cloud. There is no marketplace, no alternative provider, and no on-premises option. Committing to TPUs means committing to GCP's pricing, tooling, support model, and data residency policies. Spot TPU instances are available at lower rates but carry interruption risk for long training runs.
For GPUs, the market is much larger. AWS, Azure, GCP, Lambda, CoreWeave, Thunder Compute, and many more providers offer NVIDIA GPUs at varying price points.
If you want to minimize cost while maximizing flexibility, Thunder Compute offers NVIDIA A100 and H100 instances with on-demand pricing well below the major hyperscalers. Commitment-free, per-minute billing, and persistent storage.
TPU and GPU Cloud Pricing: What to Expect in 2026
| Accelerator | Provider | On-Demand Price (per GPU or chip hour) |
|---|---|---|
| TPU v5e | Google Cloud | $1.20-$1.56 | TPU v6e (Trillium) | Google Cloud | $2.70-$3.24 |
| TPU v5p | Google Cloud | $4.20 |
| NVIDIA A100 80 GB | Thunder Compute | $1.09 |
| NVIDIA H100 80 GB | Thunder Compute | $2.19 |
| NVIDIA A100 80 GB | AWS | $3.43 |
| NVIDIA H100 80 GB | AWS | $6.88 |
| NVIDIA A100 80 GB | Google Cloud | ~$5.07 |
| NVIDIA H100 80 GB | Google Cloud | $11.06 |
TPUs are a single-vendor product with pricing set entirely by Google. GPU pricing is shaped by real competition across providers, which keeps rates lower and gives developers leverage TPU users simply do not have.
Last Thoughts on TPU vs GPU
For most developers, GPUs are the right starting point. PyTorch works natively, hardware is available from dozens of providers, and switching providers requires no code changes. TPUs are compelling at hyperscale with the right workloads and the right Google Cloud commitment, but they carry real migration costs and vendor lock-in. The right GPU on the right provider is the most practical path for the vast majority of AI teams.
FAQ
Which Is Better in a TPU vs GPU Comparison?
GPUs are the more flexible choice for most teams. They support PyTorch natively, run on dozens of cloud providers, and work with any open-source model or library. TPUs offer better performance per watt for large-scale transformer training on Google Cloud, but require more engineering work and are locked to a single provider.
What Is a TPU?
A TPU (Tensor Processing Unit) is a custom ASIC designed by Google to accelerate tensor and matrix math. Unlike a GPU, it has no general-purpose capabilities. It exists exclusively to run neural network workloads, making it extremely efficient at scale but inflexible for anything else.
What Does TPU Stand For?
TPU stands for Tensor Processing Unit. These chips process tensors (multidimensional arrays), the fundamental data structure of every neural network architecture, from convolutional networks to transformers.
What Is the Architectural Difference Between TPUs and GPUs?
A TPU uses a systolic array: a grid of multiply-accumulate units that streams data in one direction, maximizing data reuse and reducing memory reads. A GPU uses CUDA cores in Streaming Multiprocessors paired with Tensor Cores. This makes GPUs more flexible but less efficient for pure matrix workloads.
What Is the Difference Between TPU v5e and TPU v5p?
The v5e is cost-optimized at $1.20/chip-hour with 393 trillion INT8 ops/sec/chip. The v5p targets large-scale LLM training at $4.20/chip-hour, delivering 2.8x faster training than v4 across 4,096-chip pods.
What Are the Specs of Google Ironwood (TPU v7)?
Ironwood delivers 4,614 FP8 TFLOPS per chip, 192 GB HBM3e at 7.37 TB/s memory bandwidth, and 1.2 TB/s ICI bandwidth to neighboring chips. A 9,216-chip superpod delivers 42.5 exaFLOPS at FP8, with 2x better performance per watt than Trillium.
How Do TPUs Compare to GPUs in Energy Efficiency?
TPUs have a structural efficiency advantage. Trillium v6e runs at 300W versus the H100's 700W, delivering 2-2.5x better performance per watt for transformer training. Ironwood extends that lead with 2x better perf/watt than Trillium.
Where Can You Rent Google TPUs?
TPUs are available exclusively through Google Cloud. There is no marketplace, no alternative provider, and no on-premises option. Choosing TPUs means committing to GCP's pricing, tooling, and data residency policies.
When Should You Use a TPU Instead of a GPU?
TPUs are a strong choice for training very large models (10B+ parameters) on Google Cloud with JAX, high-volume batch inference at hyperscale, and workflows native to Google's AI ecosystem (Vertex AI, BigQuery ML, Gemini APIs).
What Is TPU v8?
TPU v8, announced in April 2026, splits into two chips: TPU 8t (training, 12.6 FP4 PFLOPs, 2.8x better training cost vs Ironwood) and TPU 8i (inference, 10.1 FP4 PFLOPs, 80% better inference cost vs Ironwood). Both support native PyTorch via TorchTPU in preview. General availability is expected later in 2026.
What Is the Difference Between Trillium (TPU v6e) and Ironwood (TPU v7)?
Trillium delivers 918 BF16 TFLOPS per chip with 32 GB HBM at 1.6 TB/s. Ironwood delivers 4,614 FP8 TFLOPS with 192 GB HBM3e at 7.37 TB/s — 4x more compute per chip and 6x more memory. Ironwood adds native FP8 support and scales to 9,216-chip superpods.
Can I Use PyTorch on a TPU?
Yes, with caveats. TPUs require code to pass through the XLA compiler via PyTorch/XLA, which can mean debugging compilation traces and restructuring loops. TPU v8 chips support TorchTPU in preview, which reduces this overhead, but PyTorch on GPUs remains simpler for most teams.